
In this post, we’re excited to introduce the Chamber Ensemble Generator, a system for generating realistic chamber ensemble performances, and the corresponding CocoChorales Dataset, which contains over 1,400 hours of audio mixes with corresponding source data and MIDI, multi-f0, and per-note performance annotations.
| 🎵Audio Examples | 📝arXiv Paper | 📂Dataset Download Instructions |  Github Code Github Code |
Data is the bedrock that all machine learning systems are built upon. Historically, researchers applying machine learning to music have not had access to the same scale of data that other fields have. Whereas image and language machine learning researchers measure their datasets by the millions or billions of examples, music researchers feel extremely lucky if they can scrape together a few thousand examples for a given task.
Modern machine learning systems require large quantities of annotated data. With music systems, getting annotations for some tasks–like transcription or f0 estimation–requires tedious work by expert musicians. When annotating a single example correctly is difficult, how can we annotate hundreds of thousands of examples to make enough data to train a machine learning system?
In this post, we introduce a new approach to solving these problems by using generative models to create large amounts of realistic-sounding, finely annotated, freely available music data. We combined two structured generative models–a note generation model, Coconet, and a notes-to-audio generative synthesis model, MIDI-DDSP–into a system we call the Chamber Ensemble Generator. As its name suggests, the Chamber Ensemble Generator (or CEG) can generate performances of chamber ensembles playing in the style of four-part Bach chorales. Listen to the following examples performed by the CEG:
| String Ensemble Mixture: | |
| Soprano: Violin 1 | Alto: Violin 2 |
| Tenor: Viola | Bass: Cello |
| Woodwind Ensemble Mixture: | |
| Soprano: Flute | Alto: Oboe |
| Tenor: Clarinet | Bass: Bassoon |
We then used the CEG to create a massive music dataset for machine learning systems. We call this dataset CocoChorales. What’s exciting about the CEG is that it uses a set of structured generative models which provide annotations for many music machine learning applications like automatic music transcription, multi-f0 estimation, source separation, performance analysis, and more.
Below, we dig deeper into each of these projects.
The Chamber Ensemble Generator
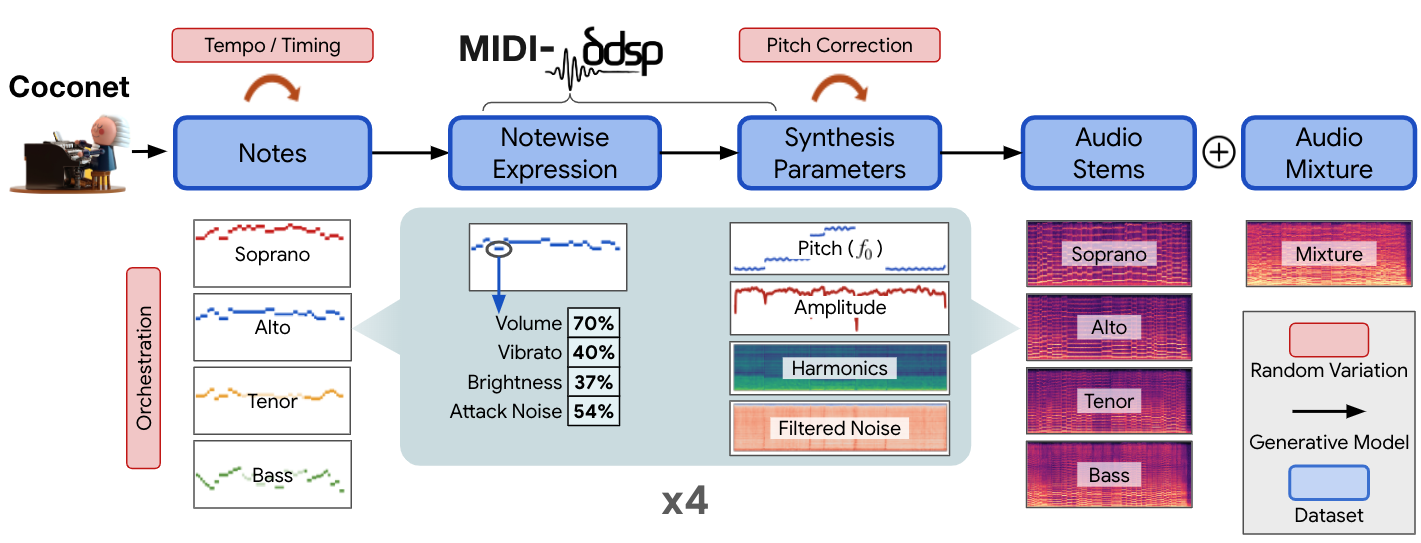
As we mentioned, the Chamber Ensemble Generator (CEG) is a set of two structured generative models that work together to create new chamber ensemble performances of four-part chorales in the style of J.S. Bach.
As seen in the figure above, the constituent models in the CEG are two previous Magenta models: Coconet and MIDI-DDSP. Coconet is a generative model of notes, creating a set of four-instrument music pieces (“note sequences”), harmonized in the style of a Bach Chorale. Each of these four note sequences is then individually synthesized by MIDI-DDSP. MIDI-DDSP is a generative synthesis model that uses Differentiable Digital Signal Processing (DDSP) that turns note sequences into realistic audio that can sound like a number of different instruments (e.g., violin, bassoon, or french horn).
It’s important to note that the CEG is built on structured generative models, i.e., models that have interpretable intermediate representations. On the one hand, this structure leads to a very opinionated view of music. The CEG is limited in ways that other generative music models are not; it cannot generate all styles of music, like a rock and roll ensemble for example. It can only generate chorales. However, many generative music models are notoriously “black boxes,” whose internal structures are difficult to interpret. By being built on a modular set of structured models, the internals of the CEG are easy to understand and modify. This also allows us to create a dataset with many types of annotations that would be tedious or impossible to acquire with other types of generative models (such as annotations of the velocity and vibrato applied to each individual note in a performance). In the next section, we will showcase how these interpretable structures can be used to mitigate biases of these generative models.
The CocoChorales Dataset
CocoChorales is a dataset of 240,000 examples totalling over 1,400 hours of mixture data. The Chamber Ensemble Generator (CEG) was used to create CocoChorales by sampling from the CEG’s two constituent generative models, Coconet and MIDI-DDSP. Using the CEG in this way is an example of dataset “amplification,” whereby a generative model trained on a small dataset is used to produce a much larger dataset. In this case, we are amplifying two very small datasets: Coconet is trained on the J.S. Bach Chorales Dataset, which contains 382 examples, and MIDI-DDSP is trained on URMP, which contains only 44 examples. But, using the CEG, we were able to generate 240,000 examples!
CocoChorales has examples performed by 13 different instruments (violin, viola, cello, double bass, flute, oboe, clarinet, bassoon, saxophone, trumpet, french horn, trombone, and tuba) organized into 4 different types of ensembles: a string ensemble, a brass ensemble, a woodwind ensemble, and a random ensemble (see the CocoChorales dataset page for more info). Each example contains an audio mixture, audio for each source, aligned MIDI, instrument labels, fundamental frequency (f0) for each instrument, notewise performance characteristics (e.g., vibrato, loudness, brightness etc of each note), and raw synthesis parameters.
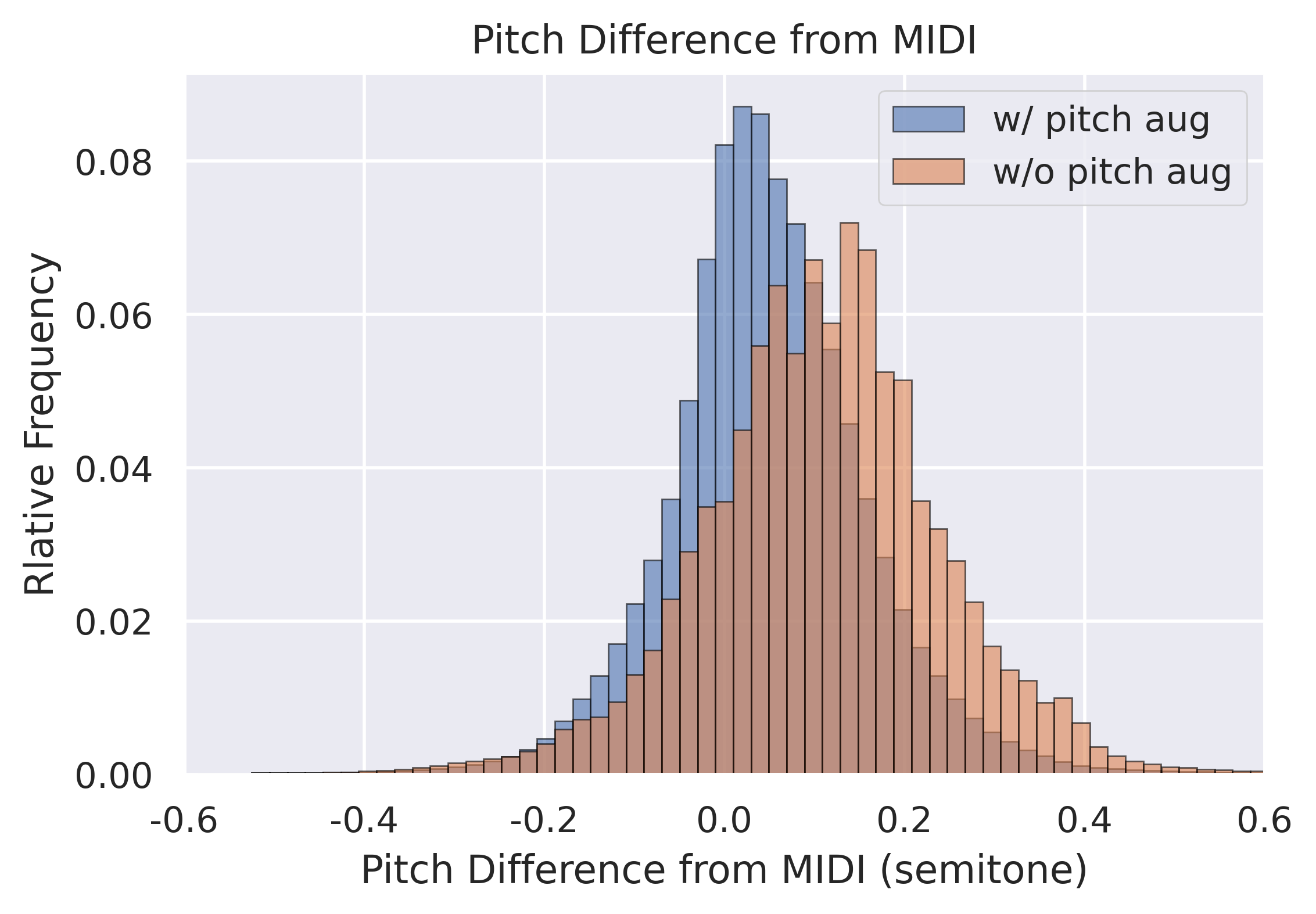
What’s cool about using the structured models in the CEG, is that because the system is modular, it is easy to interpret the output of the intermediate steps of the internal CEG models. For example, the MIDI-DDSP model we used tended to produce performances that were oftentimes out of tune and skewed sharp (i.e., frequency of a note being played was often slightly higher than the “proper” tuned frequency of the note in the piece, according to a 12-TET scale). This is visualized by the orange histogram in the above image (labeled “w/o pitch aug”), which shows how in or out of tune each note is once every 4ms (here, 0.0 means perfectly “in tune”). We were able to correct for this systematic bias by directly adjusting the f0 curves output by the synthesis generation module of the MIDI-DDSP model, as shown by the blue histogram (labeled “w/ pitch aug”), which shows a distribution that is more centered on 0.0 in the figure above. This level of control is hard to achieve with black box generative models, and a big reason why we’re very excited about using the structured models in the CEG.
Downloading the Dataset
We’re really excited to see what the research community can do with the CocoChorales dataset. Further details on the dataset can be found here. Instructions on how to download the dataset can be found at this Github link.
If you want to learn more about either project, please see our arXiv paper. The code for the Chamber Ensemble Generator is available here and usage instructions are here. If you use the Chamber Ensemble Generator or CocoChorales in a research publication, we kindly ask that you use the following bibtex entry to cite it:
@article{wu2022chamber,
title = {The Chamber Ensemble Generator: Limitless High-Quality MIR Data via Generative Modeling},
author = {Wu, Yusong and Gardner, Josh and Manilow, Ethan and Simon, Ian and Hawthorne, Curtis and Engel, Jesse},
journal={arXiv preprint arXiv:2209.14458},
year = {2022},
}