Blog posts
-
 Magenta RealTime 2: Open & Local Live Music ModelsMagenta RealTime 2 is an open-source framework for developing real-time, interactive applications, powered by our new state-of-the-art open-weights live music model.June 4, 2026
Magenta RealTime 2: Open & Local Live Music ModelsMagenta RealTime 2 is an open-source framework for developing real-time, interactive applications, powered by our new state-of-the-art open-weights live music model.June 4, 2026 -
 Open-sourcing The Infinite Crate DAW pluginToday we're fully open sourcing The Infinite Crate, a DAW plugin built on the Lyria RealTime API, for developers to fork, modify, and make their own under the Apache 2.0 license.March 9, 2026
Open-sourcing The Infinite Crate DAW pluginToday we're fully open sourcing The Infinite Crate, a DAW plugin built on the Lyria RealTime API, for developers to fork, modify, and make their own under the Apache 2.0 license.March 9, 2026 -
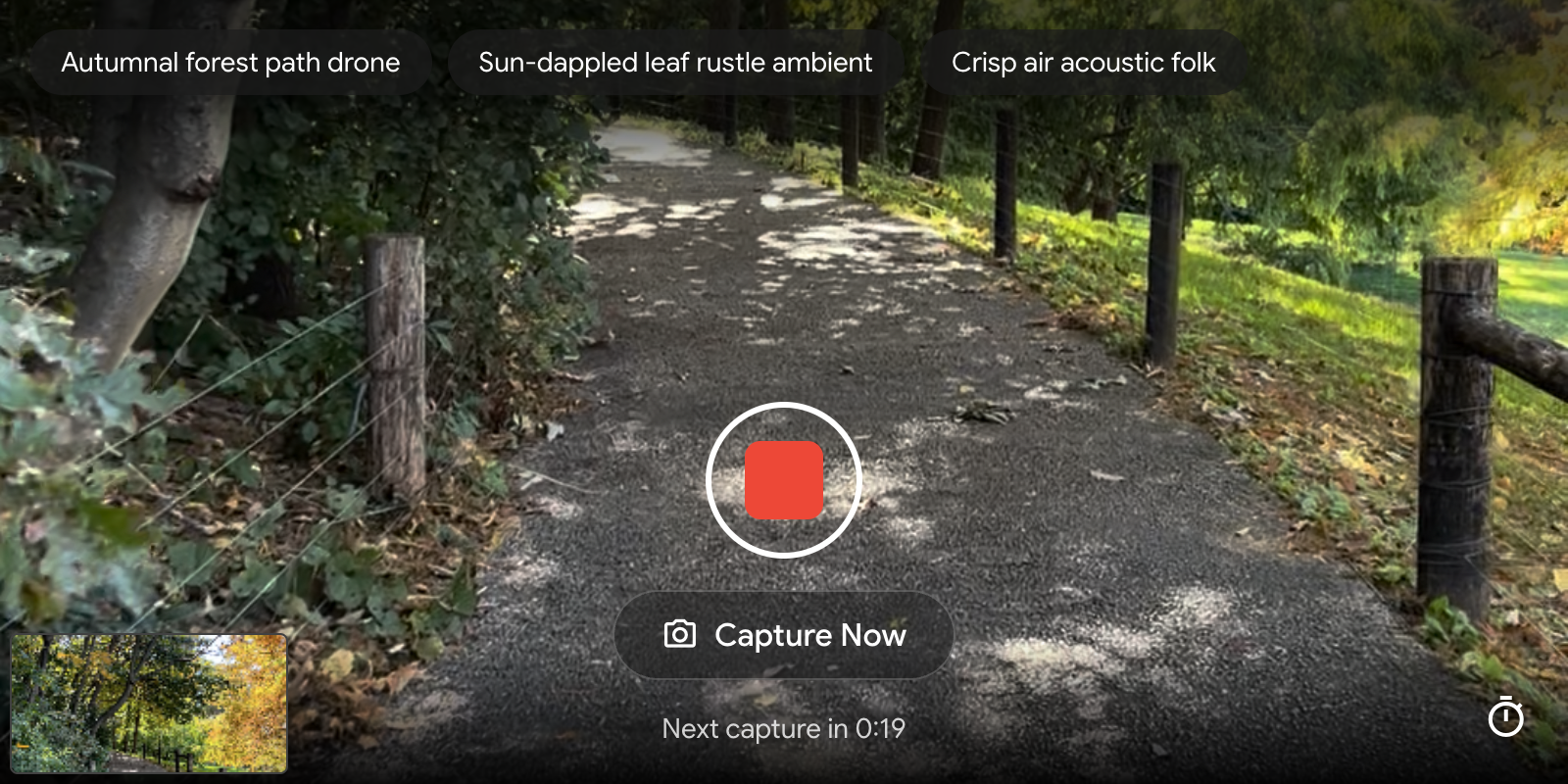 Lyria Camera: Soundtrack your lifeLyria Camera is an app that uses Lyria RealTime to make music with your camera. By combining Gemini’s image understanding and the Lyria RealTime API, Lyria Camera generates a musical score that adapts to your environment.December 3, 2025
Lyria Camera: Soundtrack your lifeLyria Camera is an app that uses Lyria RealTime to make music with your camera. By combining Gemini’s image understanding and the Lyria RealTime API, Lyria Camera generates a musical score that adapts to your environment.December 3, 2025 -
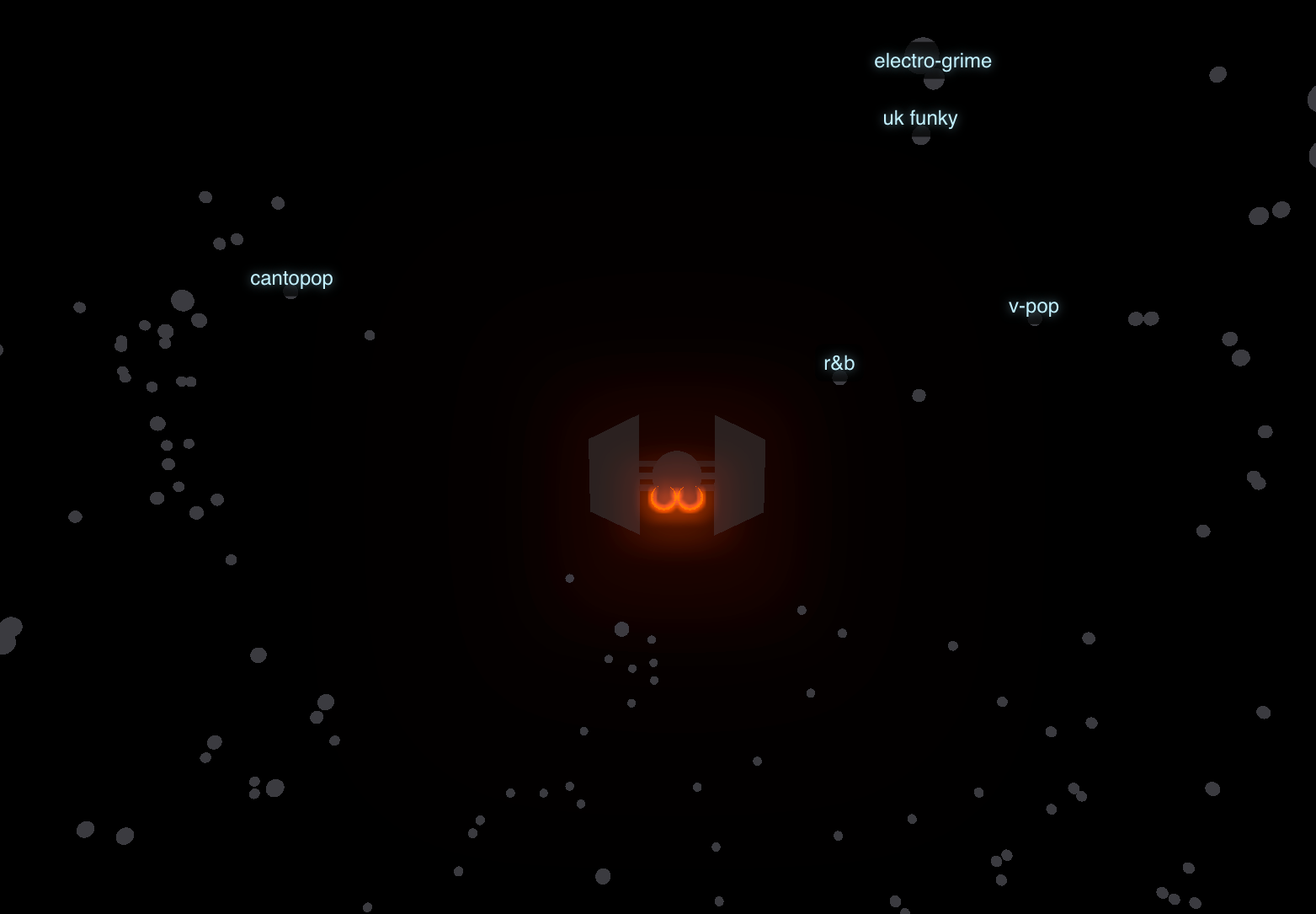 Space DJ: Navigating a Musical UniverseSpace DJ is a web application that turns music exploration into an interactive journey through a constellation of sounds. Pilot a spaceship through a galaxy where each star represents a musical genre, and Space DJ will use the Lyria RealTime API to generate a continuous stream of music in real-time.November 3, 2025
Space DJ: Navigating a Musical UniverseSpace DJ is a web application that turns music exploration into an interactive journey through a constellation of sounds. Pilot a spaceship through a galaxy where each star represents a musical genre, and Space DJ will use the Lyria RealTime API to generate a continuous stream of music in real-time.November 3, 2025 -
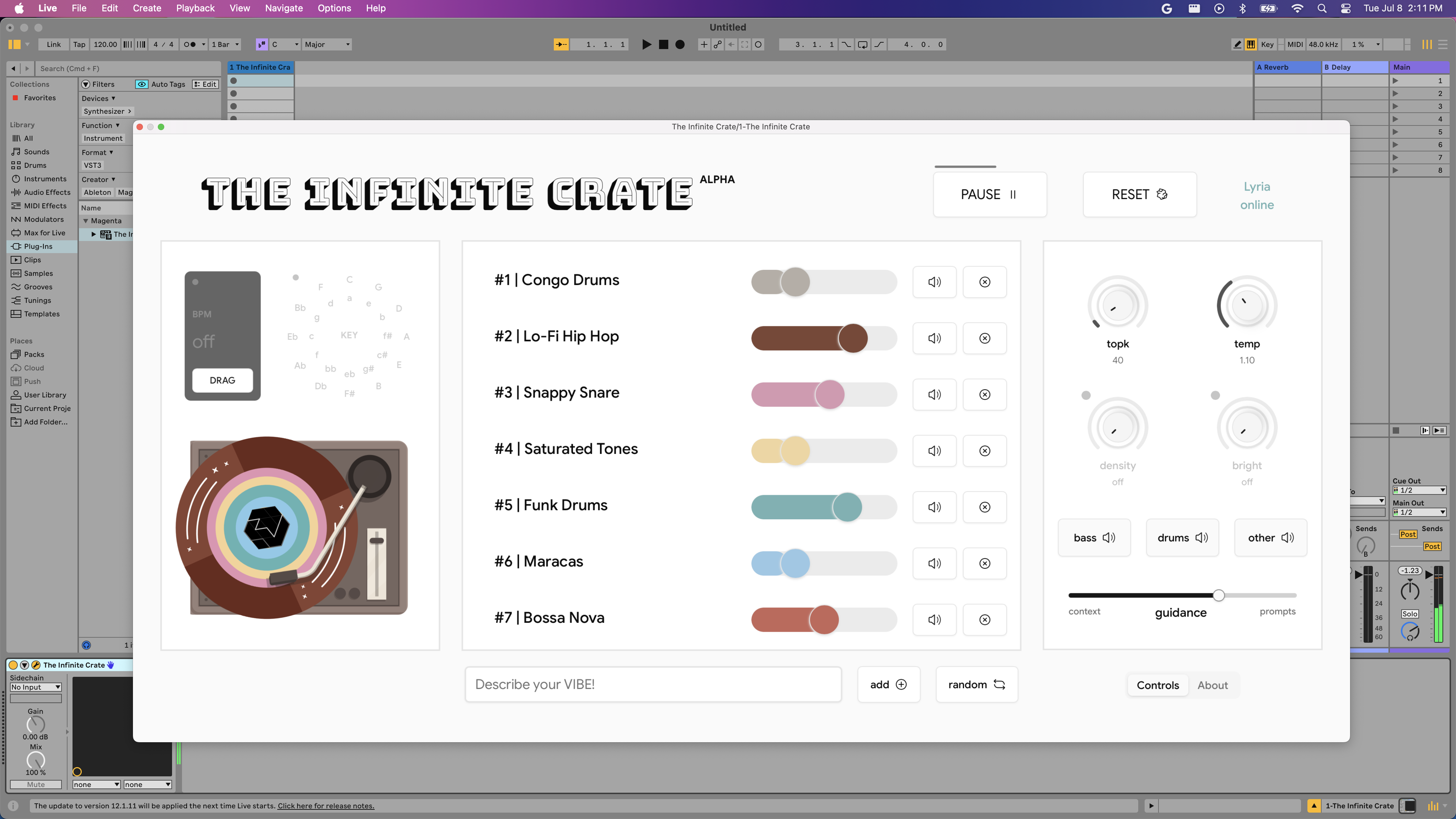 Lyria RealTime VST: The Infinite CrateThe Infinite Crate is a DAW plugin prototype built on the Lyria RealTime live music model in the Gemini API. The plugin allows users to mix together text prompts to steer a live music model in real-time, feeding audio directly into your DAW for sampling, live performance, or a backing track to jam with.July 9, 2025
Lyria RealTime VST: The Infinite CrateThe Infinite Crate is a DAW plugin prototype built on the Lyria RealTime live music model in the Gemini API. The plugin allows users to mix together text prompts to steer a live music model in real-time, feeding audio directly into your DAW for sampling, live performance, or a backing track to jam with.July 9, 2025 -
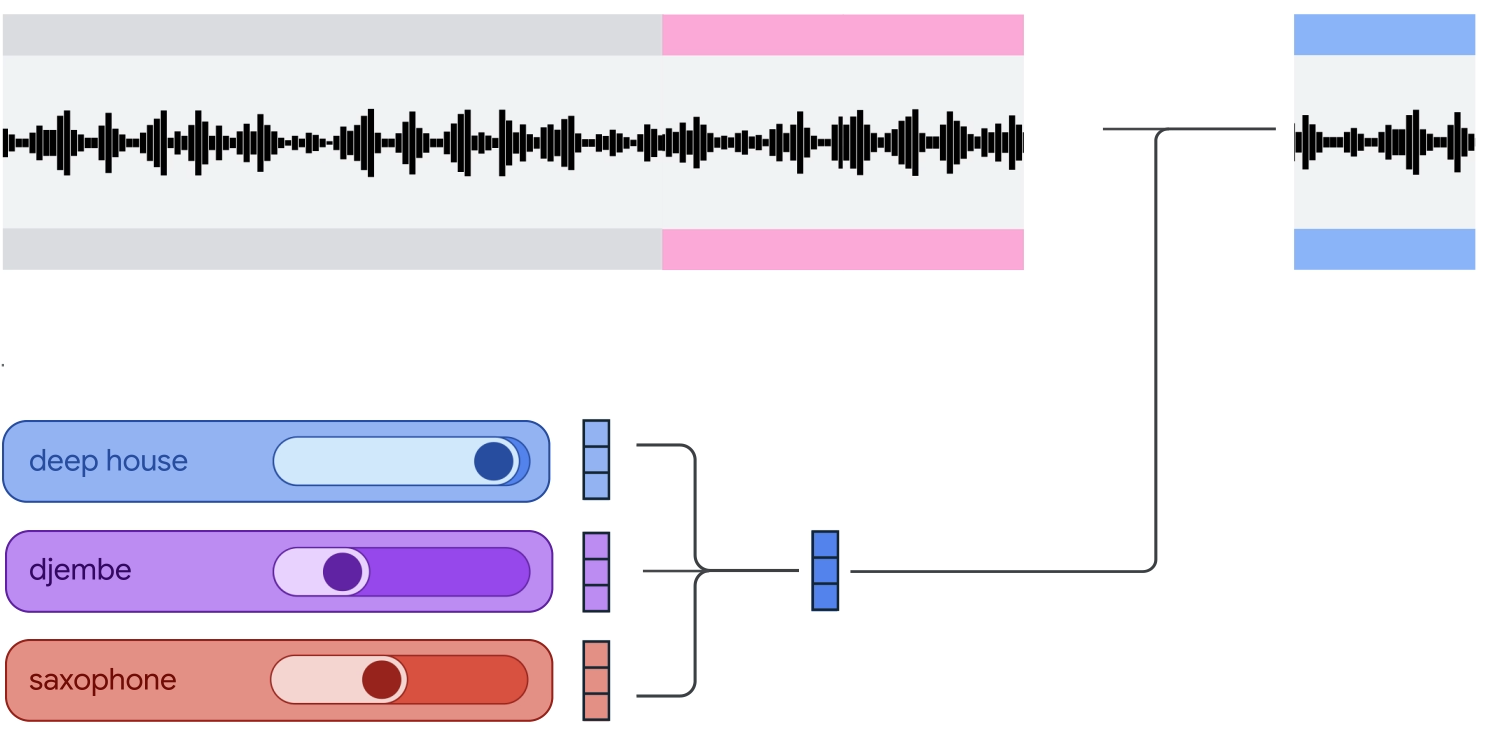 Magenta RealTime: An Open-Weights Live Music ModelWe’re happy to share a research preview of Magenta RealTime (Magenta RT), an open-weights live music model that allows you to interactively create, control and perform music in the moment.June 20, 2025
Magenta RealTime: An Open-Weights Live Music ModelWe’re happy to share a research preview of Magenta RealTime (Magenta RT), an open-weights live music model that allows you to interactively create, control and perform music in the moment.June 20, 2025 -
 Introducing Lyria RealTime APIIntroducing the Lyria RealTime API, a new experimental tool offering real-time control over a generative AI music model, enabling users to explore and create dynamic music experiences through text prompts and various musical parameters.June 12, 2025
Introducing Lyria RealTime APIIntroducing the Lyria RealTime API, a new experimental tool offering real-time control over a generative AI music model, enabling users to explore and create dynamic music experiences through text prompts and various musical parameters.June 12, 2025 -
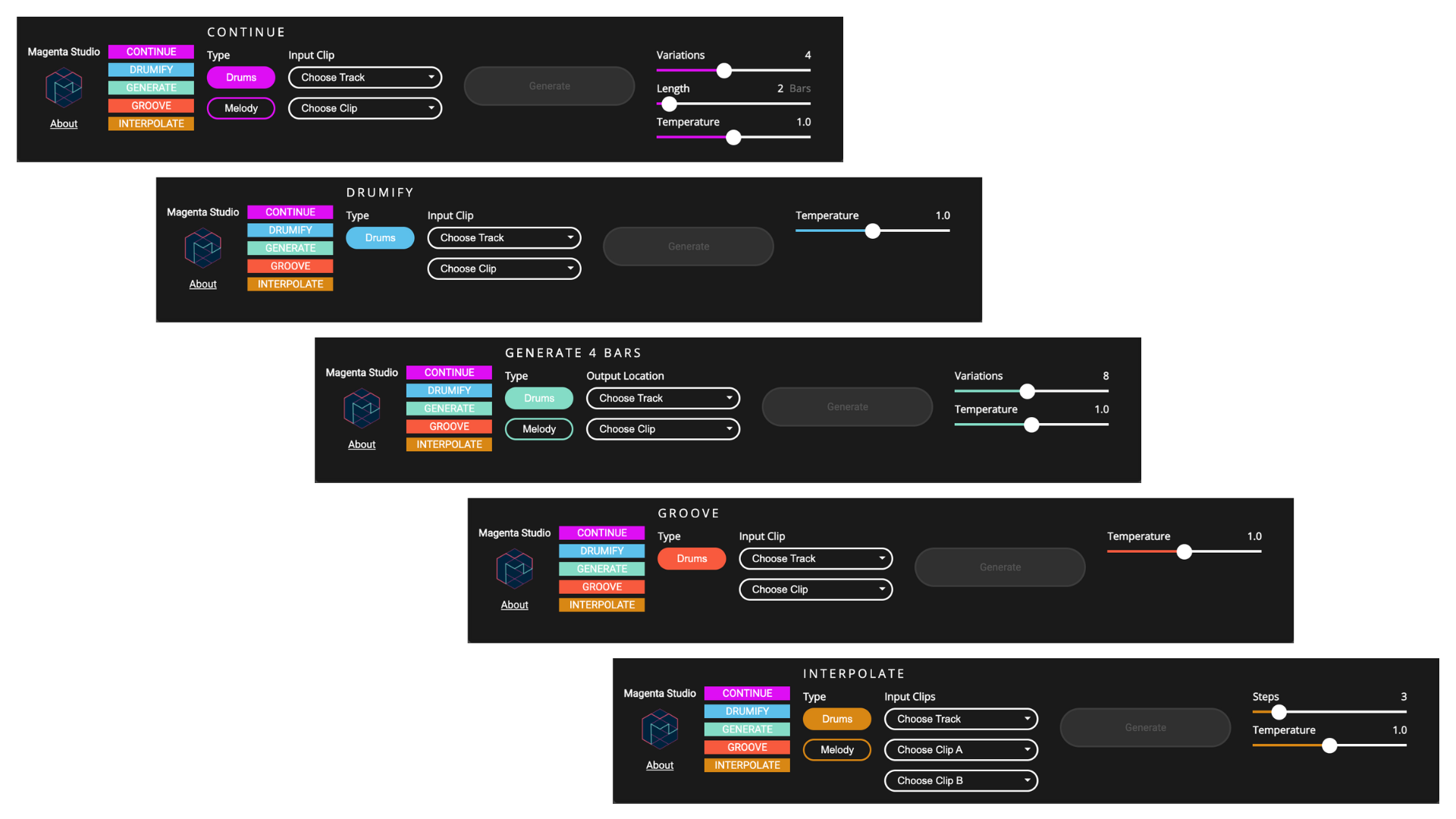 Magenta Studio 2.0Magenta Studio has been upgraded to more seamlessly integrate with Ableton Live. It is a collection of music creativity tools built on Magenta’s open source models, using cutting-edge machine learning techniques for music generation.August 24, 2023
Magenta Studio 2.0Magenta Studio has been upgraded to more seamlessly integrate with Ableton Live. It is a collection of music creativity tools built on Magenta’s open source models, using cutting-edge machine learning techniques for music generation.August 24, 2023 -
 The 2023 I/O Preshow – Composed by Dan Deacon (with some help from MusicLM)A look into Dan Deacon's creative process for the 2023 Google I/O preshow.June 21, 2023
The 2023 I/O Preshow – Composed by Dan Deacon (with some help from MusicLM)A look into Dan Deacon's creative process for the 2023 Google I/O preshow.June 21, 2023 -
 The Wordcraft Writers Workshop: Creative Co-Writing with AIWe invited 13 professional writers to explore the limits of co-writing with LaMDA and foster an honest and earnest conversation about the rapidly changing relationship between technology and creativity.December 1, 2022
The Wordcraft Writers Workshop: Creative Co-Writing with AIWe invited 13 professional writers to explore the limits of co-writing with LaMDA and foster an honest and earnest conversation about the rapidly changing relationship between technology and creativity.December 1, 2022 -
 The Chamber Ensemble Generator and CocoChorales DatasetWe combine Coconet and MIDI-DDSP into a system called the Chamber Ensemble Generator, which we use to make a giant dataset of four-part Bach chorales called CocoChorales.September 30, 2022
The Chamber Ensemble Generator and CocoChorales DatasetWe combine Coconet and MIDI-DDSP into a system called the Chamber Ensemble Generator, which we use to make a giant dataset of four-part Bach chorales called CocoChorales.September 30, 2022 -
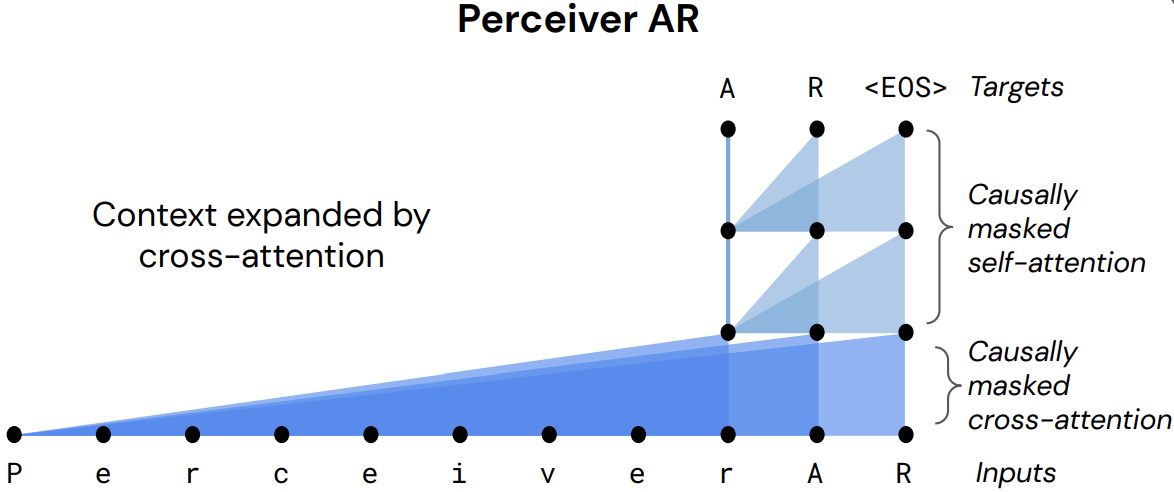 Autoregressive long-context music generation with Perceiver ARWe generate music with clear long-term coherence and structure in both symbolic and audio domains, by attending to inputs spanning up to several minutes.June 16, 2022
Autoregressive long-context music generation with Perceiver ARWe generate music with clear long-term coherence and structure in both symbolic and audio domains, by attending to inputs spanning up to several minutes.June 16, 2022 -
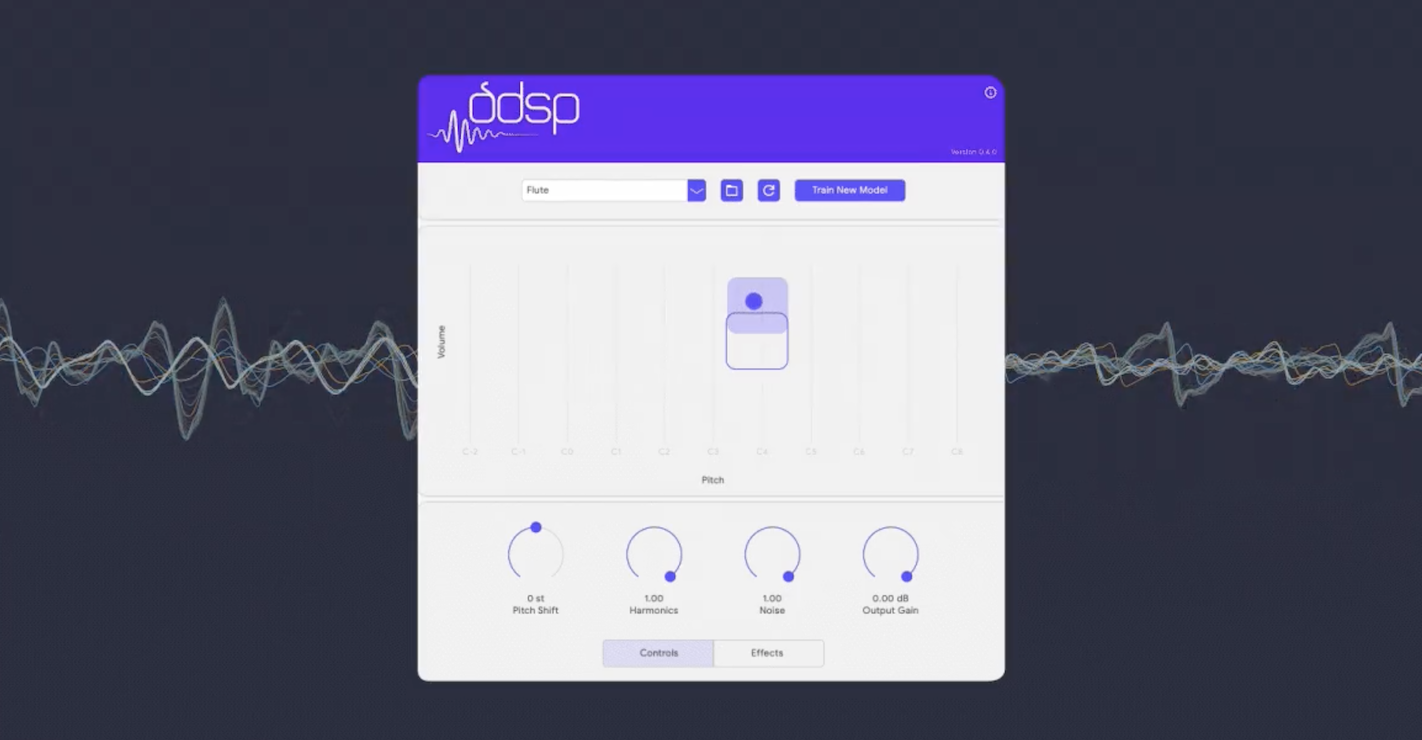 DDSP-VST: Neural Audio Synthesis for AllDDSP-VST is a neural audio synthesizer for your digital audio workstation, powered by DDSP.June 8, 2022
DDSP-VST: Neural Audio Synthesis for AllDDSP-VST is a neural audio synthesizer for your digital audio workstation, powered by DDSP.June 8, 2022 -
MIDI-DDSP: Detailed Control of Musical Performance via Hierarchical ModelingWe show a hierarchical extension of DDSP to use note and expressive performance conditioning.January 20, 2022
-
 Paint With MusicTurn your paint brush into musical instruments and compose on sensorial canvases!January 6, 2022
Paint With MusicTurn your paint brush into musical instruments and compose on sensorial canvases!January 6, 2022 -
 HCI and ML: Putting People FirstWe highlight work done in collaboration with Human Computer Interaction (HCI) colleagues that optimize models for human values.December 15, 2021
HCI and ML: Putting People FirstWe highlight work done in collaboration with Human Computer Interaction (HCI) colleagues that optimize models for human values.December 15, 2021 -
 Modern Evolution Strategies for CreativityModern evolution to artistically fit concreate images and abstract concepts.November 18, 2021
Modern Evolution Strategies for CreativityModern evolution to artistically fit concreate images and abstract concepts.November 18, 2021 -
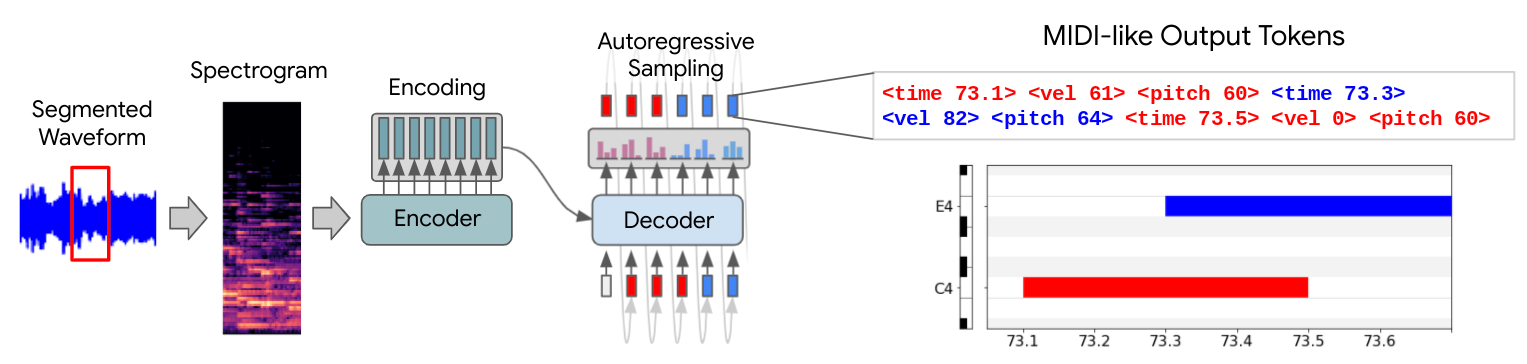 Music Transcription with TransformersWe discuss Magenta's research into using off-the-shelf Transformer models for music transcription.November 9, 2021
Music Transcription with TransformersWe discuss Magenta's research into using off-the-shelf Transformer models for music transcription.November 9, 2021 -
 Hip-Hop EP co-produced using Machine LearningIn this guest post, MJ Jacob discusses how he used Magenta models in the process of creating his new EP.May 26, 2021
Hip-Hop EP co-produced using Machine LearningIn this guest post, MJ Jacob discusses how he used Magenta models in the process of creating his new EP.May 26, 2021 -
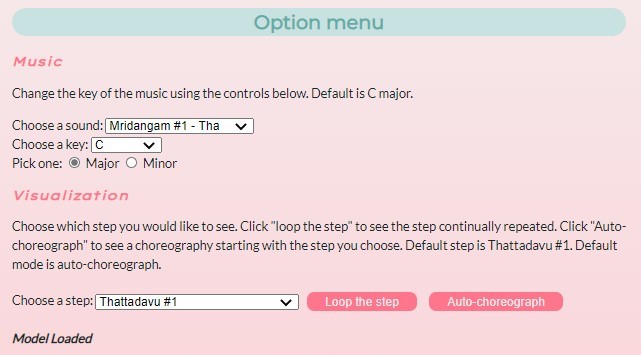 Natya*MLThrough Natya*ML, I sought to showcase the beauty of Bharatanatyam in a way that’s easy and understandable.January 28, 2021
Natya*MLThrough Natya*ML, I sought to showcase the beauty of Bharatanatyam in a way that’s easy and understandable.January 28, 2021 -
 Maestro: An AI-guided vocal coachWe leveraged the Magenta.js library to create Maestro, an application that combines music theory with practical lessons for music enthusiasts.January 26, 2021
Maestro: An AI-guided vocal coachWe leveraged the Magenta.js library to create Maestro, an application that combines music theory with practical lessons for music enthusiasts.January 26, 2021 -
 DearDiary.aiType some words—thoughts, feelings, poems, goals, stories, a to-do list—and you’ve created an original song.January 22, 2021
DearDiary.aiType some words—thoughts, feelings, poems, goals, stories, a to-do list—and you’ve created an original song.January 22, 2021 -
 BitRate: RecapLast year, Magenta and Gray Area partnered to host BitRate, a month-long series focused on experimenting with the possibilities of Music and Machine Learning.January 20, 2021
BitRate: RecapLast year, Magenta and Gray Area partnered to host BitRate, a month-long series focused on experimenting with the possibilities of Music and Machine Learning.January 20, 2021 -
 Stepping Towards Transcultural Machine Learning in MusicHow can we move towards building creative technology for all?January 12, 2021
Stepping Towards Transcultural Machine Learning in MusicHow can we move towards building creative technology for all?January 12, 2021 -
 AI Song Contest: Human-AI Co-Creation in SongwritingWhat are the challenges in using AI as a tool in songwriting? What are the design implications?October 13, 2020
AI Song Contest: Human-AI Co-Creation in SongwritingWhat are the challenges in using AI as a tool in songwriting? What are the design implications?October 13, 2020 -
 Tone TransferTransform everyday sounds into musical instruments. Record and hear yourself as flutes, saxophones and more!October 1, 2020
Tone TransferTransform everyday sounds into musical instruments. Record and hear yourself as flutes, saxophones and more!October 1, 2020 -
 Lo-Fi PlayerA magical room where you can interact with music and have fun. Explore the possibilities by tinkering with the objects in the room.September 1, 2020
Lo-Fi PlayerA magical room where you can interact with music and have fun. Explore the possibilities by tinkering with the objects in the room.September 1, 2020 -
 The Musician in the MachineGuest blogger Dan Jeffries discusses how he and his team dug deep to find out if neural nets can compose Ambient music with the great masters of the art.August 7, 2020
The Musician in the MachineGuest blogger Dan Jeffries discusses how he and his team dug deep to find out if neural nets can compose Ambient music with the great masters of the art.August 7, 2020 -
 BitRate: Machine Learning & Music SeriesThis August, Magenta and the Bay Area non-profit Gray Area present BitRate, a month-long series focused on experimenting with the possibilities of Music and Machine Learning.July 31, 2020
BitRate: Machine Learning & Music SeriesThis August, Magenta and the Bay Area non-profit Gray Area present BitRate, a month-long series focused on experimenting with the possibilities of Music and Machine Learning.July 31, 2020 -
 Make a song togetherWork together with friends to create your very own piece of music!April 30, 2020
Make a song togetherWork together with friends to create your very own piece of music!April 30, 2020 -
 Improving Perceptual Quality of Drum Transcription with the Expanded Groove MIDI DatasetOaF Drums enables high precision automatic drum transcription with included velocity prediction.April 2, 2020
Improving Perceptual Quality of Drum Transcription with the Expanded Groove MIDI DatasetOaF Drums enables high precision automatic drum transcription with included velocity prediction.April 2, 2020 -
 Making an Album with Music TransformerNobody's songs is an album composed with the help of Magenta’s Music Transformer.February 18, 2020
Making an Album with Music TransformerNobody's songs is an album composed with the help of Magenta’s Music Transformer.February 18, 2020 -
 Listen to TransformerAn app to make it easier to explore and curate samples from a piano transformer.February 13, 2020
Listen to TransformerAn app to make it easier to explore and curate samples from a piano transformer.February 13, 2020 -
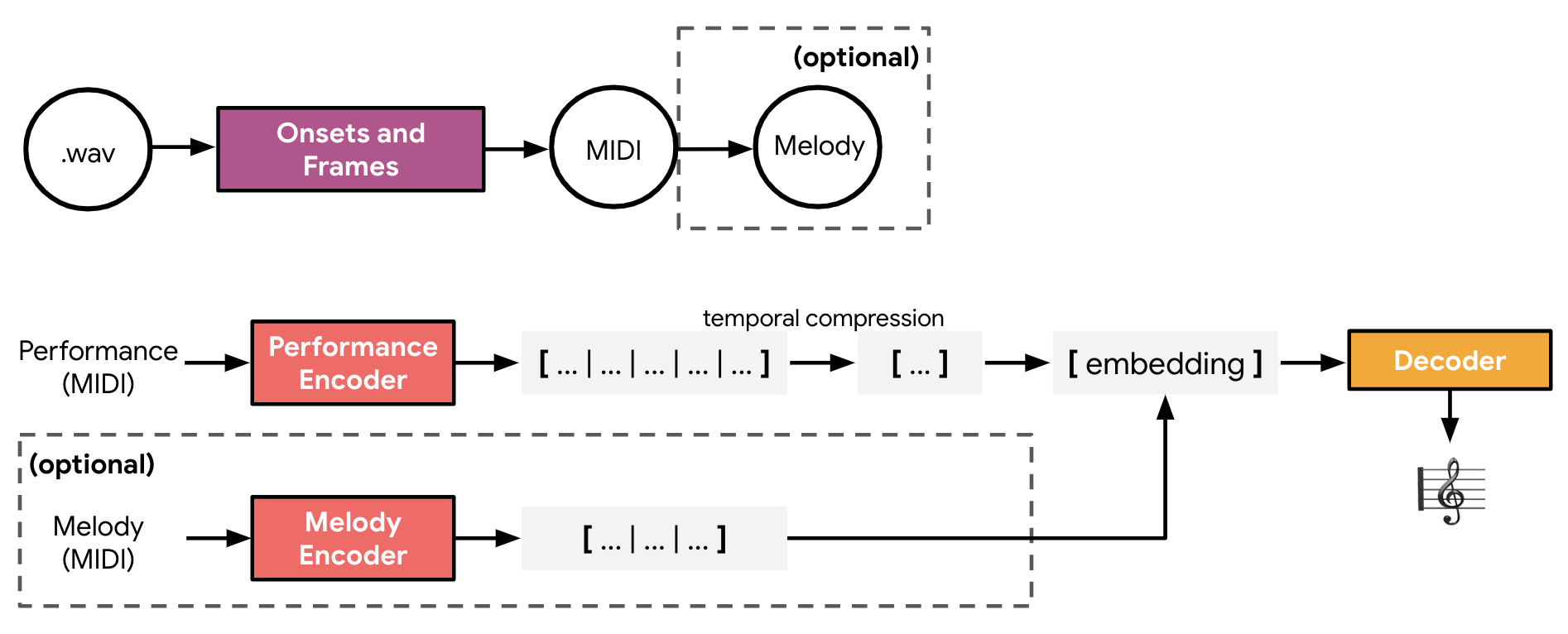 Encoding Musical Style with Transformer AutoencodersWe introduce the Transformer autoencoder, allowing control over both the global and local structure of a generated music sample.January 22, 2020
Encoding Musical Style with Transformer AutoencodersWe introduce the Transformer autoencoder, allowing control over both the global and local structure of a generated music sample.January 22, 2020 -
 DDSP: Differentiable Digital Signal ProcessingFusing interpretable digital signal processing with end-to-end learning.January 15, 2020
DDSP: Differentiable Digital Signal ProcessingFusing interpretable digital signal processing with end-to-end learning.January 15, 2020 -
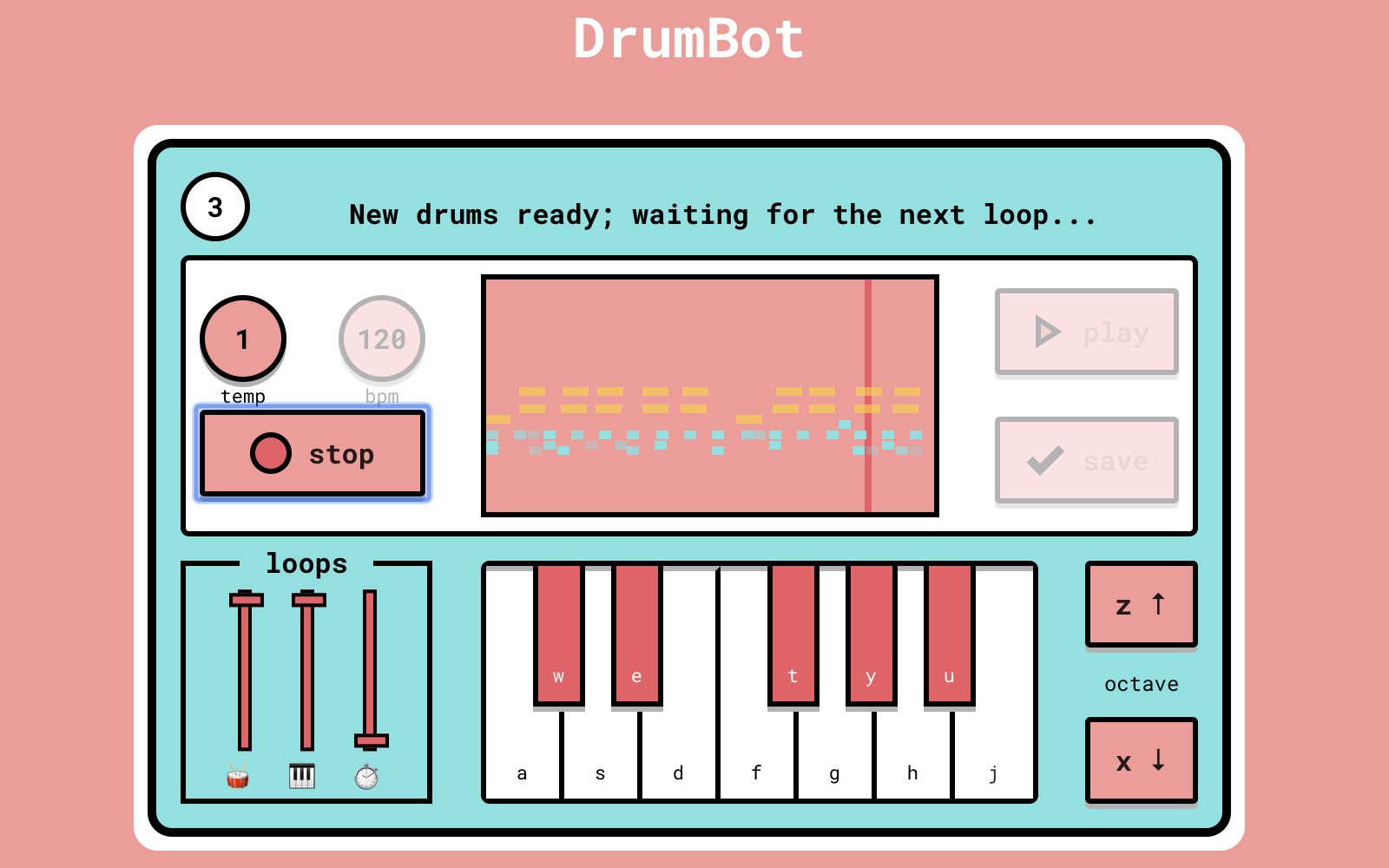 DrumBot: your real-time ML drummerPlay real-time music with a Machine Learning drummer that drums based on your melody.December 2, 2019
DrumBot: your real-time ML drummerPlay real-time music with a Machine Learning drummer that drums based on your melody.December 2, 2019 -
 SVG VAE: Generating Scalable Vector Graphics TypographyCode, Colab notebook and data open-sourced for ML-assisted SVG generation of fonts.October 15, 2019
SVG VAE: Generating Scalable Vector Graphics TypographyCode, Colab notebook and data open-sourced for ML-assisted SVG generation of fonts.October 15, 2019 -
 Generating Piano Music with TransformerInteractive Colab notebook for generating piano performances.September 16, 2019
Generating Piano Music with TransformerInteractive Colab notebook for generating piano performances.September 16, 2019 -
 YACHT's new album is powered by ML + ArtistsThe LA-based dance-pop trio YACHT just released their new album, a collaboration with Magenta and other ML researchers and artists.September 13, 2019
YACHT's new album is powered by ML + ArtistsThe LA-based dance-pop trio YACHT just released their new album, a collaboration with Magenta and other ML researchers and artists.September 13, 2019 -
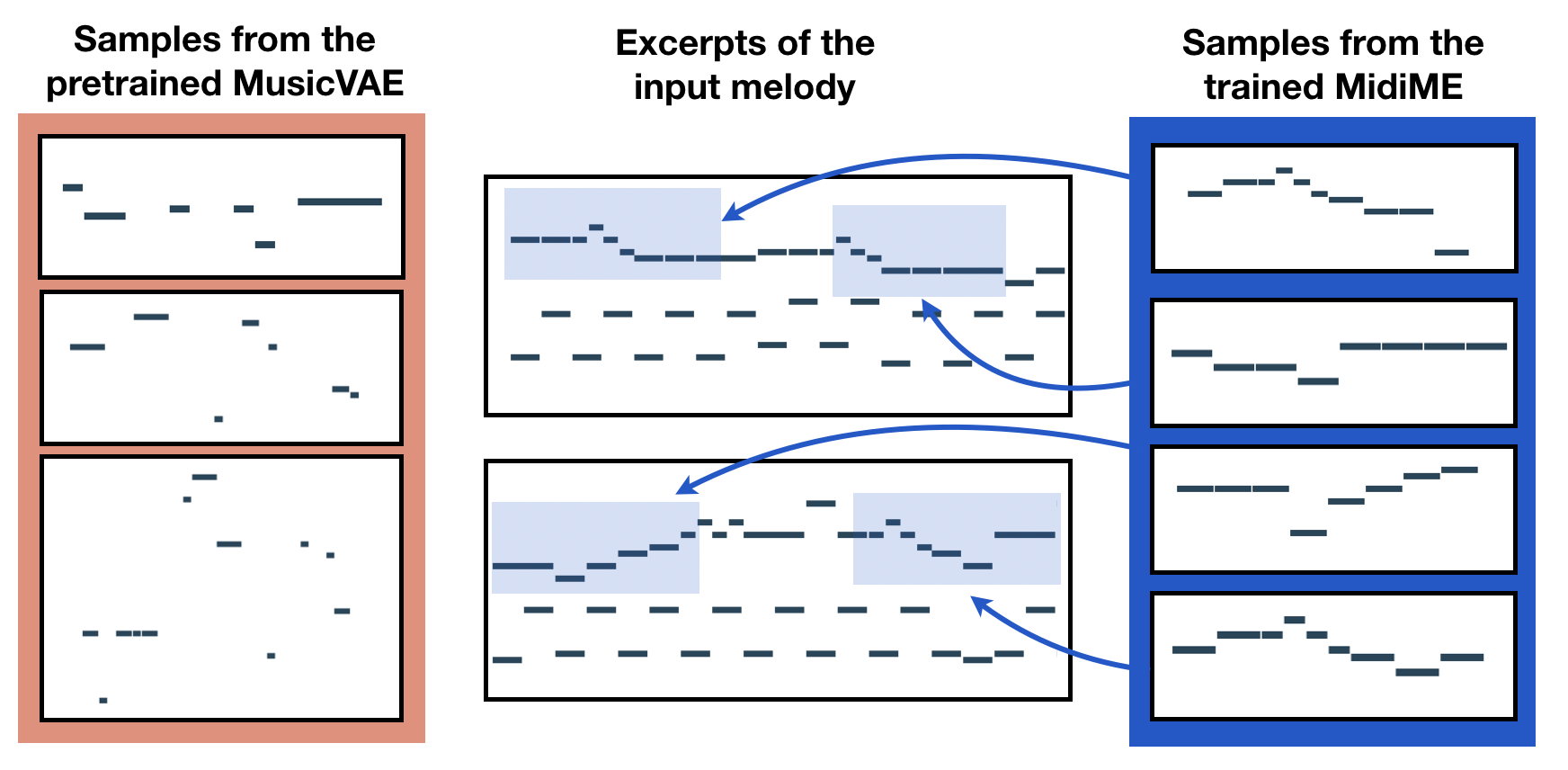 MidiMe: Personalizing MusicVAEA machine learning experiment to train a small model to sound like you.July 23, 2019
MidiMe: Personalizing MusicVAEA machine learning experiment to train a small model to sound like you.July 23, 2019 -
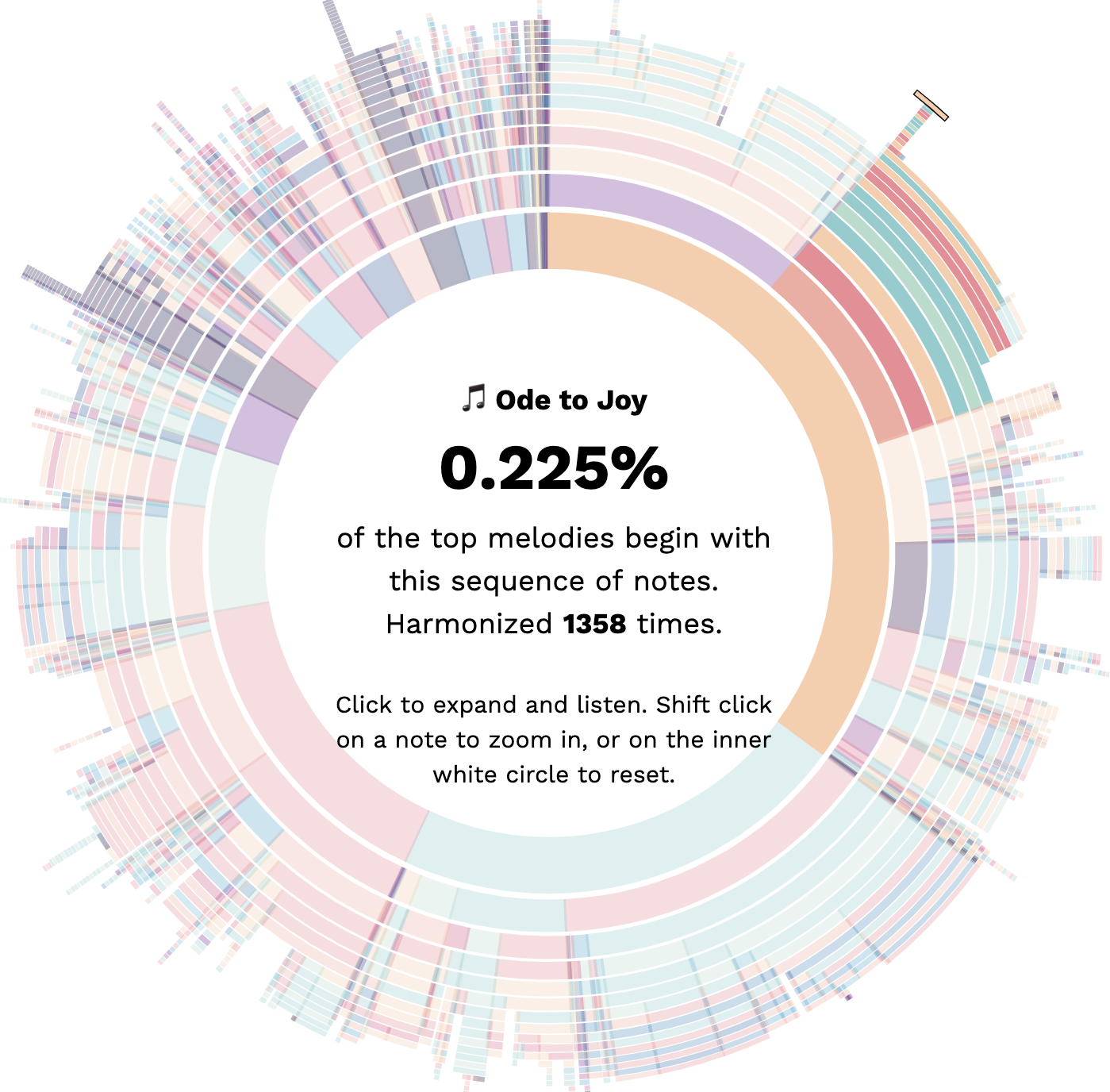 Visualizing the Bach Doodle DatasetInteractive visualizations of the Bach Doodle compositions.July 16, 2019
Visualizing the Bach Doodle DatasetInteractive visualizations of the Bach Doodle compositions.July 16, 2019 -
 ML-Jam: Performing Structured Improvisations with Pre-trained ModelsInteractive jamming with machine learning models.June 19, 2019
ML-Jam: Performing Structured Improvisations with Pre-trained ModelsInteractive jamming with machine learning models.June 19, 2019 -
 Magenta + Deeplocal +
Magenta + Deeplocal +
The Flaming Lips = Fruit GenieCreating an AI-assisted performance as part of the headline concert at I/O 2019.May 13, 2019 -
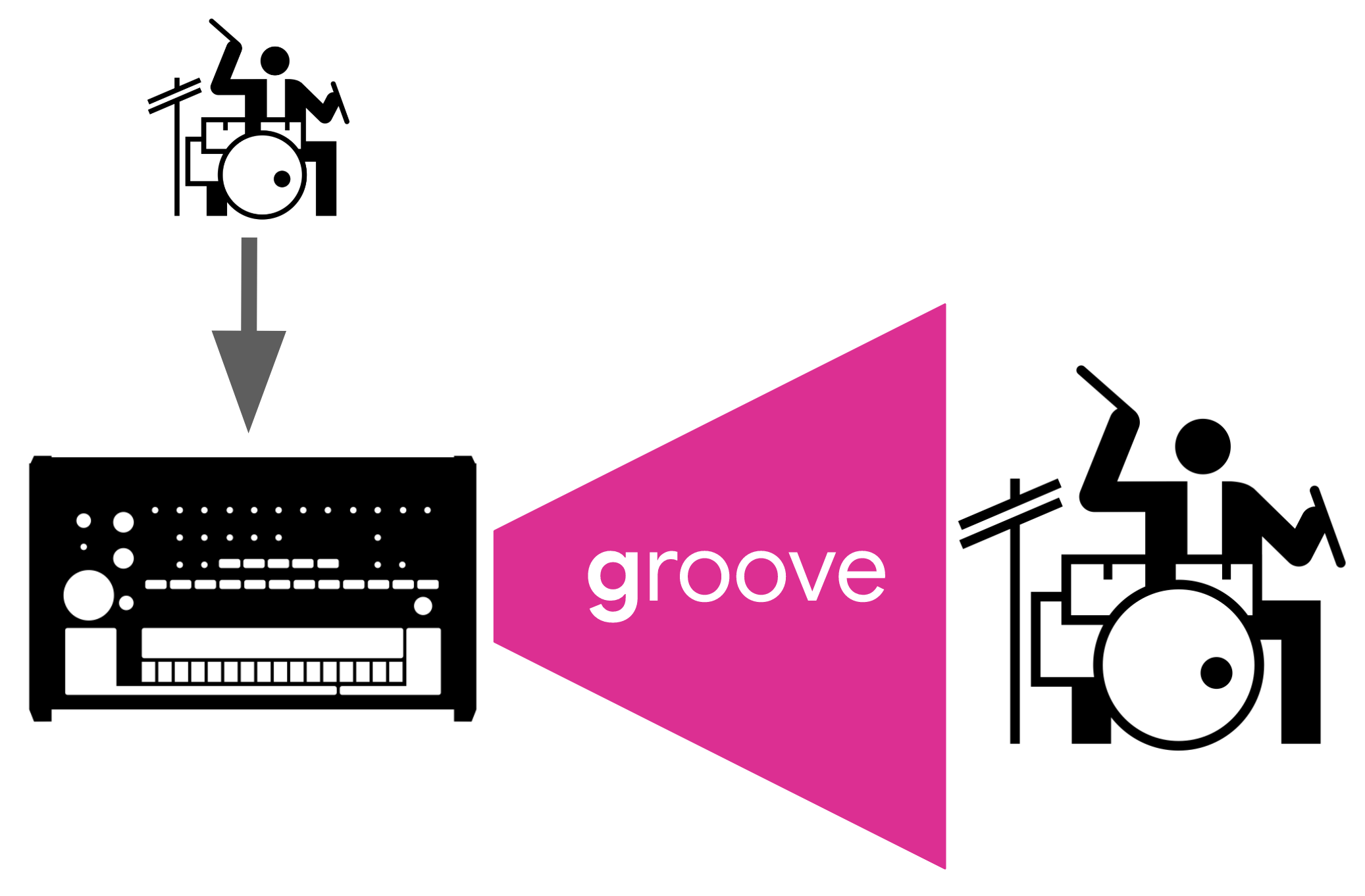 GrooVAE: Generating and Controlling Expressive Drum PerformancesGrooVAE models expressive drumming.May 2, 2019
GrooVAE: Generating and Controlling Expressive Drum PerformancesGrooVAE models expressive drumming.May 2, 2019 -
 WiMIR Workshop 2018Building Bridges at WiMIR 2018.April 22, 2019
WiMIR Workshop 2018Building Bridges at WiMIR 2018.April 22, 2019 -
 Coconet: the ML model behind today’s Bach DoodleWe present Coconet, the ML model behind today's Bach Doodle. It is a versatile model of counterpoint that can infill arbitrary missing parts by rewriting the musical score multiple times to improve its internal consistency.March 20, 2019
Coconet: the ML model behind today’s Bach DoodleWe present Coconet, the ML model behind today's Bach Doodle. It is a versatile model of counterpoint that can infill arbitrary missing parts by rewriting the musical score multiple times to improve its internal consistency.March 20, 2019 -
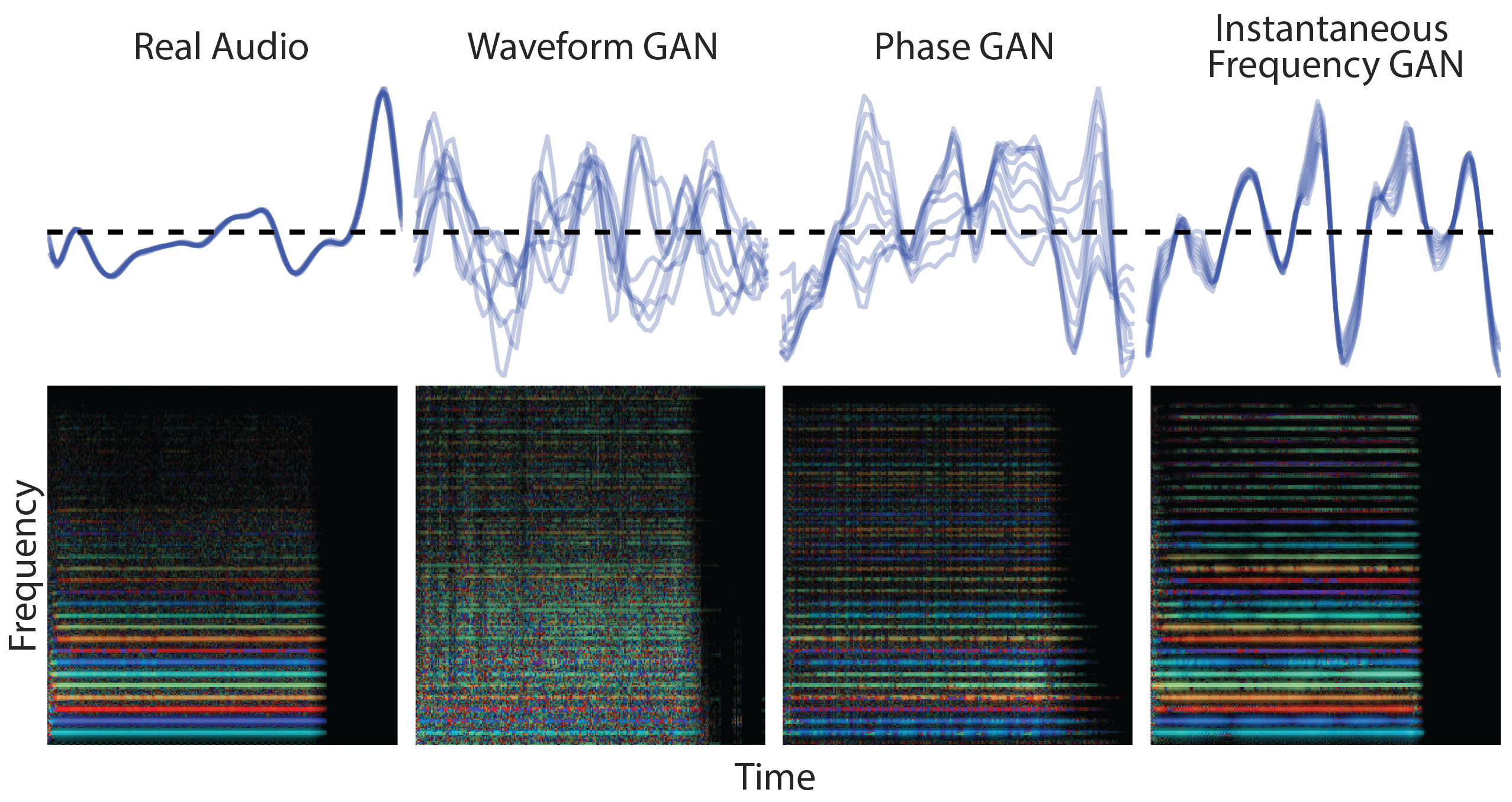 GANSynth: Making music with GANsGANSynth enables high-fidelity audio synthesis with GANs.February 25, 2019
GANSynth: Making music with GANsGANSynth enables high-fidelity audio synthesis with GANs.February 25, 2019 -
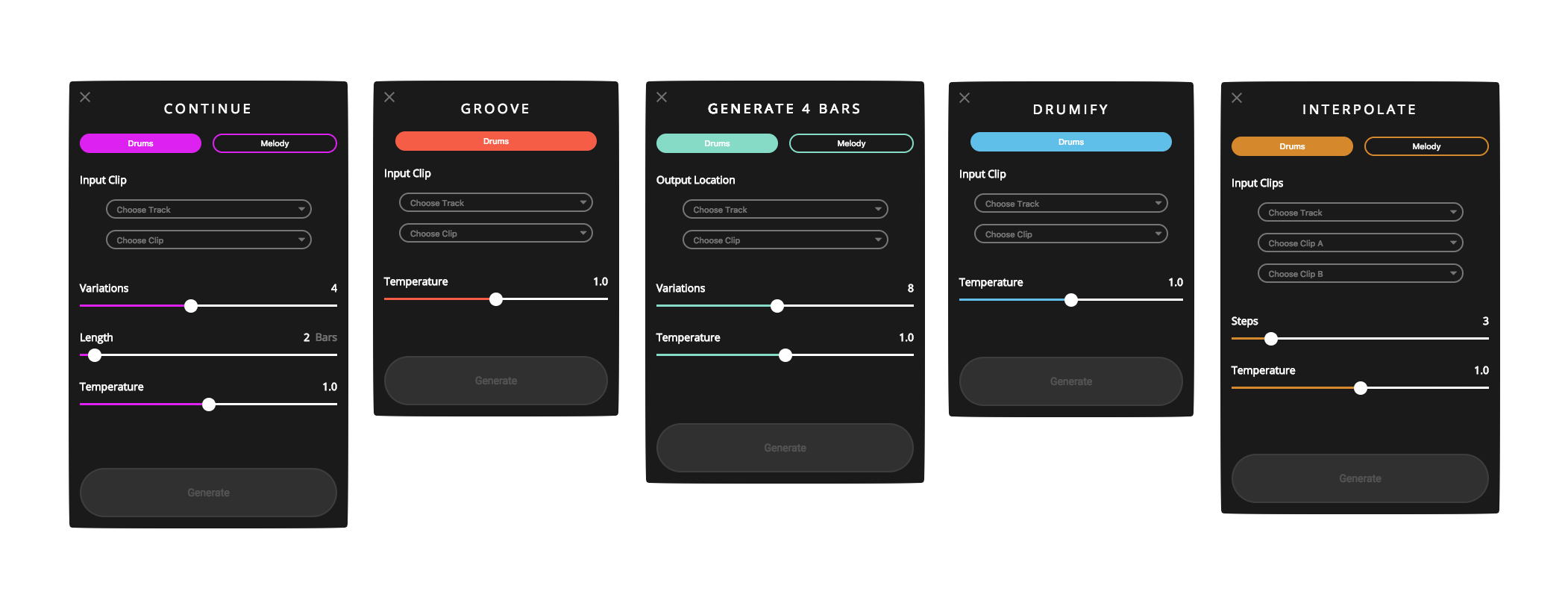 Magenta StudioMagenta Studio is a collection of music creativity tools built on Magenta’s open source models, available both as standalone applications and as plugins for Ableton Live. They use cutting-edge machine learning techniques for music generation.February 12, 2019
Magenta StudioMagenta Studio is a collection of music creativity tools built on Magenta’s open source models, available both as standalone applications and as plugins for Ableton Live. They use cutting-edge machine learning techniques for music generation.February 12, 2019 -
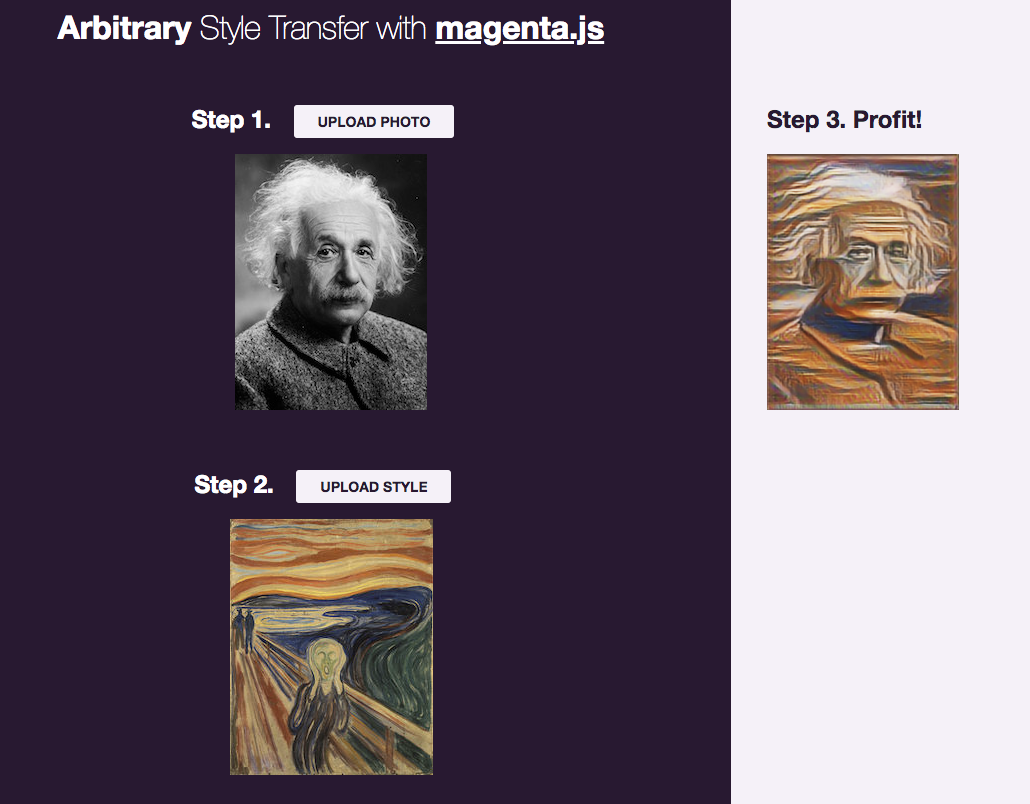 Porting Arbitrary Style Transfer to the BrowserReiichiro Nakano describes how he contributed arbitrary image style transfer to Magenta.js using model distillation to improve performance in the browser.December 20, 2018
Porting Arbitrary Style Transfer to the BrowserReiichiro Nakano describes how he contributed arbitrary image style transfer to Magenta.js using model distillation to improve performance in the browser.December 20, 2018 -
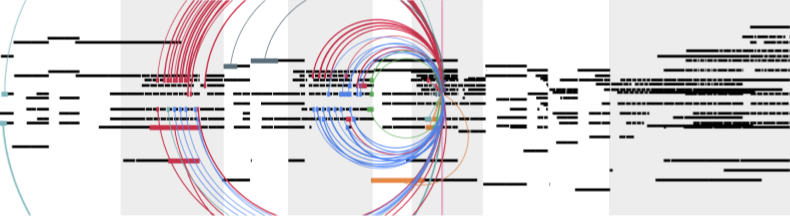 Music Transformer: Generating Music with Long-Term StructureWe present Music Transformer, a self-attention-based neural network that can generate music with long-term coherence.December 13, 2018
Music Transformer: Generating Music with Long-Term StructureWe present Music Transformer, a self-attention-based neural network that can generate music with long-term coherence.December 13, 2018 -
 ML as Collaborator: Composing Melodic Palettes with Latent LoopsCatherine McCurry, a musician and a creative technologist with Google’s Pie Shop, writes about designing tools that help musicians make use of Magenta’s musical models.November 6, 2018
ML as Collaborator: Composing Melodic Palettes with Latent LoopsCatherine McCurry, a musician and a creative technologist with Google’s Pie Shop, writes about designing tools that help musicians make use of Magenta’s musical models.November 6, 2018 -
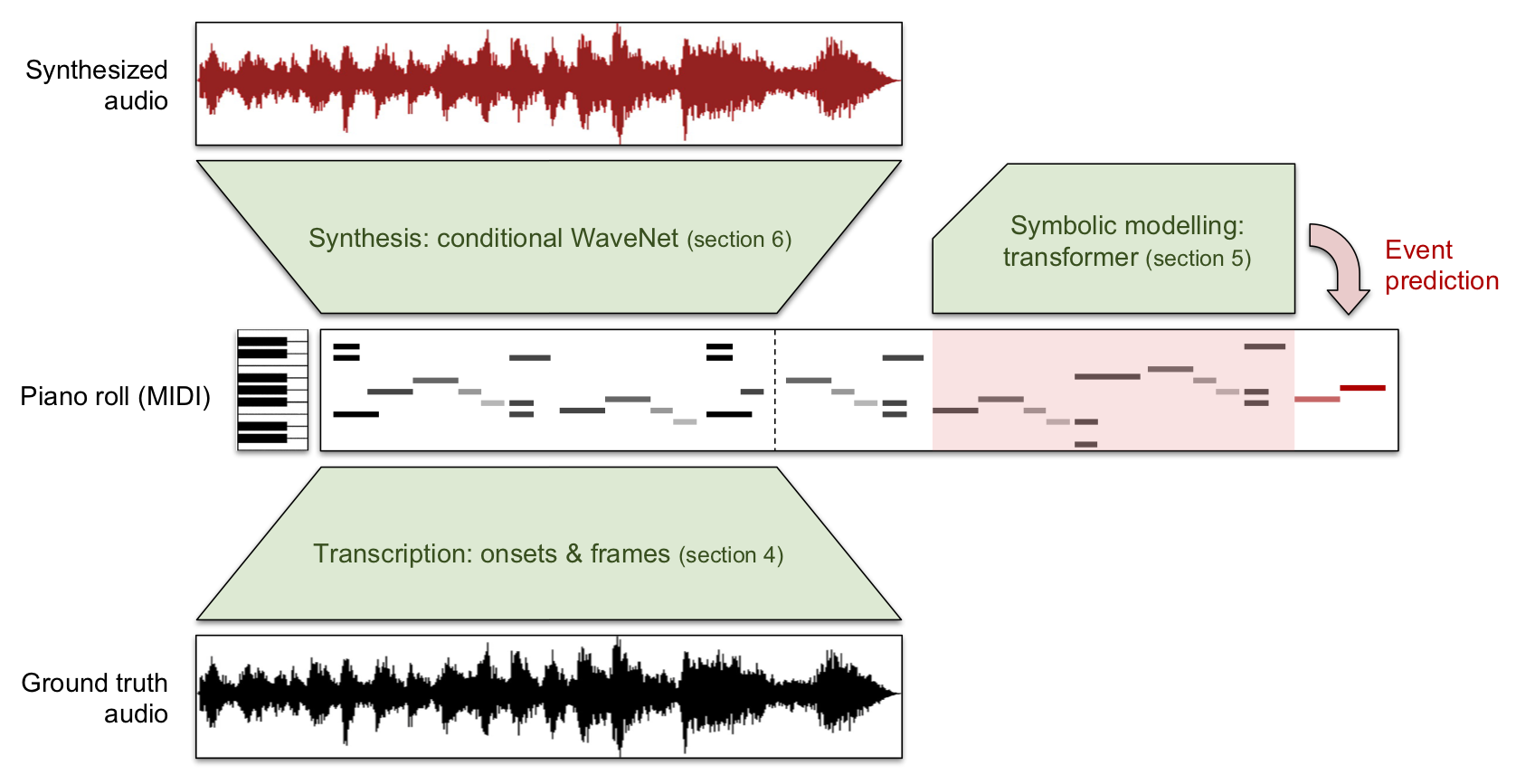 The MAESTRO Dataset and Wave2Midi2WaveMAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) is a new dataset composed of over 172 hours of virtuosic piano performances captured with fine alignment (~3 ms) between note labels and audio waveforms.October 30, 2018
The MAESTRO Dataset and Wave2Midi2WaveMAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) is a new dataset composed of over 172 hours of virtuosic piano performances captured with fine alignment (~3 ms) between note labels and audio waveforms.October 30, 2018 -
 Piano Genie: An Intelligent Musical InterfaceWe introduce Piano Genie, an intelligent controller that maps 8-button input to a full 88-key piano in real time.October 15, 2018
Piano Genie: An Intelligent Musical InterfaceWe introduce Piano Genie, an intelligent controller that maps 8-button input to a full 88-key piano in real time.October 15, 2018 -
A train windowInspired by Steve Reich’s Music for 18 musicians, Damien Henry uses machine learning to create a visual to go along with it.October 3, 2018
-
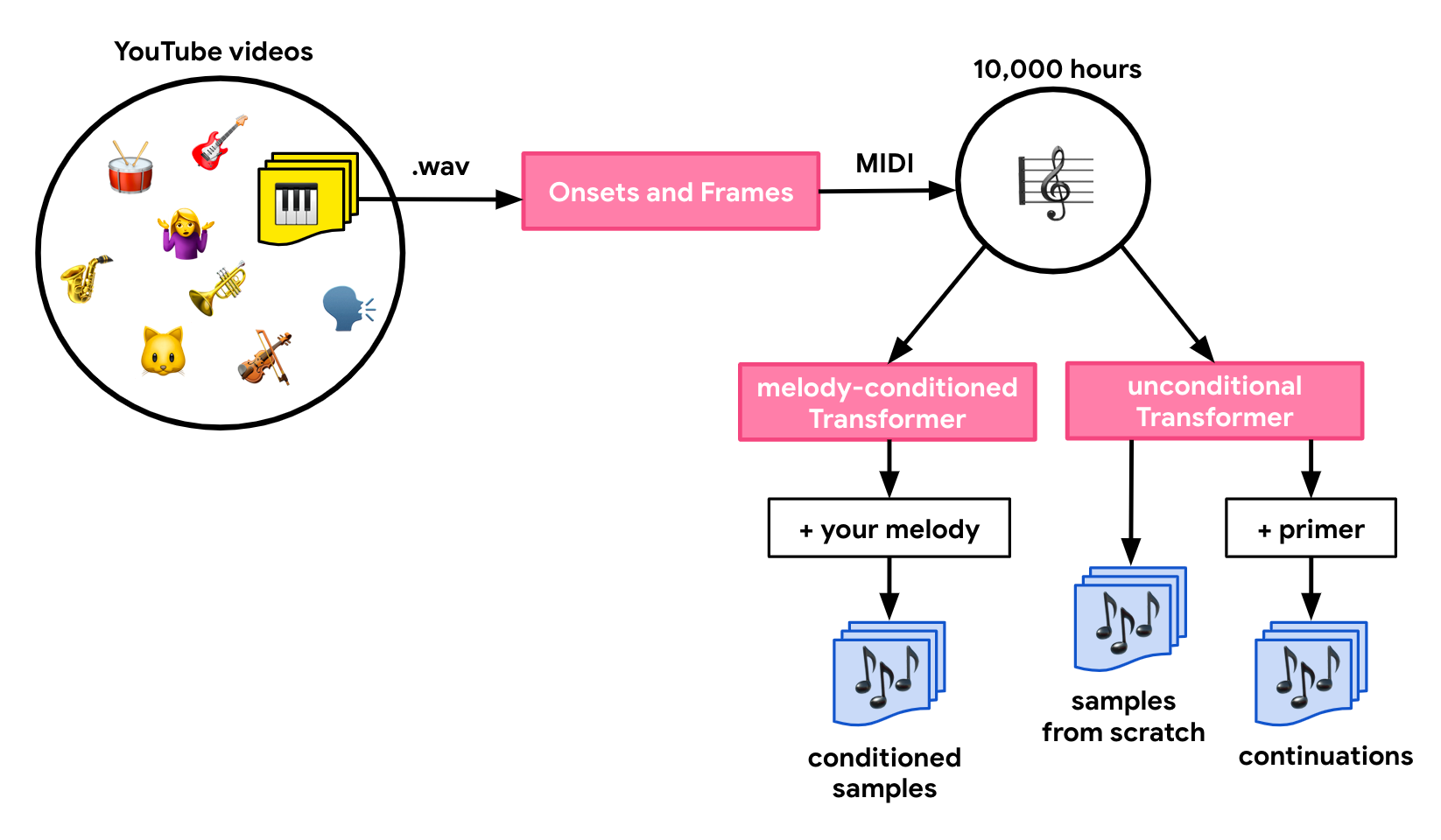
 Piano Transcription in the Browser with Onsets and FramesMany of the generative models in Magenta.js require music to be input as a symbolic representation like MIDI; but what if you only have audio?September 20, 2018
Piano Transcription in the Browser with Onsets and FramesMany of the generative models in Magenta.js require music to be input as a symbolic representation like MIDI; but what if you only have audio?September 20, 2018 -
 June 5, 2018
June 5, 2018 -
 May 3, 2018
May 3, 2018 -
 May 2, 2018
May 2, 2018 -
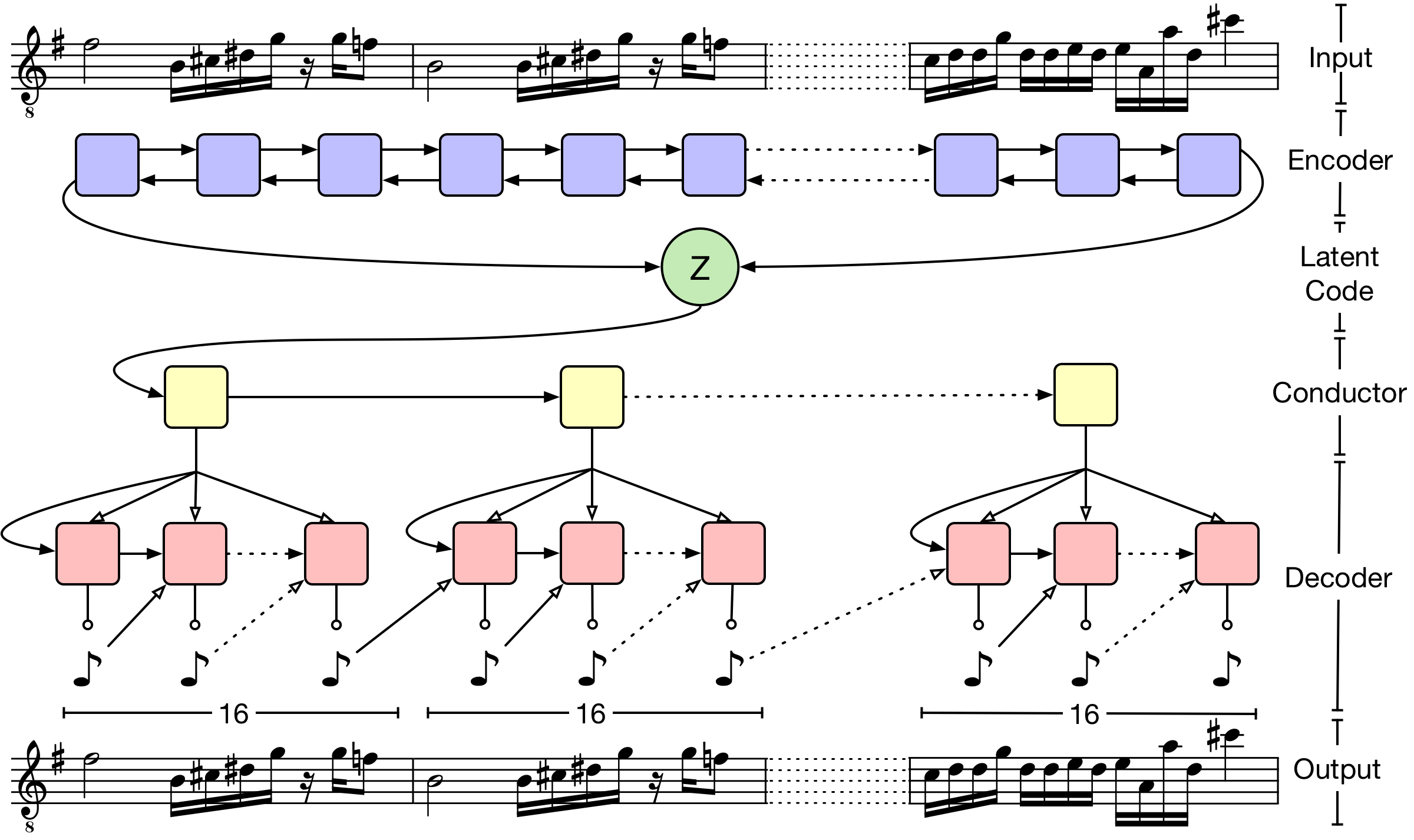 March 15, 2018
March 15, 2018 -
 March 13, 2018
March 13, 2018 -
February 12, 2018
-
 October 5, 2017
October 5, 2017 -
September 12, 2017
-
 June 29, 2017
June 29, 2017 -
 June 26, 2017
June 26, 2017 -
June 19, 2017
-
June 1, 2017
-
May 18, 2017
-
May 18, 2017
-
April 6, 2017
-
March 16, 2017
-
February 16, 2017
-
December 16, 2016
-
November 9, 2016
-
November 1, 2016
-
September 23, 2016
-
August 2, 2016
-
July 15, 2016
-
July 11, 2016
-
June 29, 2016
-
June 10, 2016
-
June 1, 2016