Today, we’re pleased to introduce the Differentiable Digital Signal Processing (DDSP) library. DDSP lets you combine the interpretable structure of classical DSP elements (such as filters, oscillators, reverberation, etc.) with the expressivity of deep learning.
 GitHub Code GitHub Code |
🎵Audio Examples |  Colab Demo Colab Demo |
Colab Tutorials |
📝ICLR Paper |
Neural networks (such as WaveNet or GANSynth) are often black boxes. They can adapt to different datasets but often overfit details of the dataset and are difficult to interpret. Interpretable models (such as musical grammars) use known structure, so they are easier to understand, but have trouble adapting to diverse datasets.
DSP (Digital Signal Processing, without the extra “differentiable” D) is one of the backbones of modern society, integral to telecommunications, transportation, audio, and many medical technologies. You could fill many books with DSP knowledge, but here are some fun introductions to audio signals, oscillators, and filters, if this is new to you.
The key idea is to use simple interpretable DSP elements to create complex realistic signals by precisely controlling their many parameters. For example, a collection of linear filters and sinusoidal oscillators (DSP elements) can create the sound of a realistic violin if the frequencies and responses are tuned in just the right way. However, it is difficult to dynamically control all of these parameters by hand, which is why synthesizers with simple controls often sound unnatural and “synthetic”.
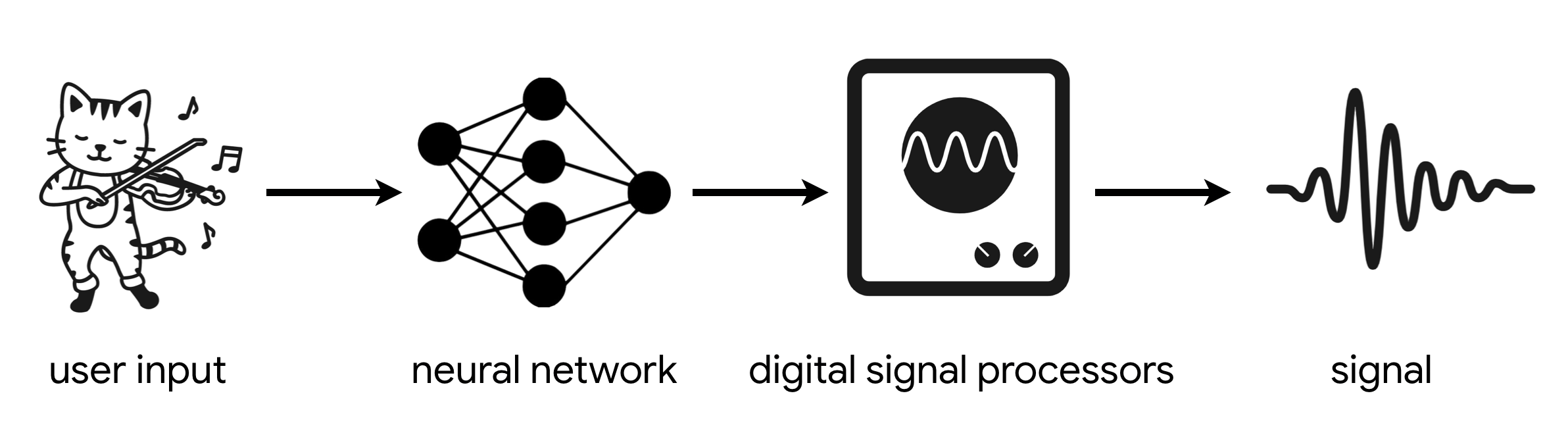
With DDSP, we use a neural network to convert a user’s input into complex DSP controls that can produce more realistic signals. This input could be any form of control signal, including features extracted from audio itself. Since the DDSP units are differentiable (thus the extra D), we can then train the neural network to adapt to a dataset through standard backpropagation.
What can we do with it?
In our ICLR 2020 paper we show that using differentiable oscillators, filters, and reverberation from the DDSP library enables us to train high-quality audio synthesis models with less data and fewer parameters, as they do not need to learn to generate audio from scratch. For example in the samples below, all the models were trained on less than 13 minutes of audio. Also, since the DDSP components are interpretable and modular, we can extend to a range of fun behaviors such as blind dereverberation, extrapolation to pitches not in the training set, and timbre transfer between disparate sources. Below are some examples of timbre transfer, keeping the frequency and loudness the same and changing the character of the instrument’s sound, including turning our AI Resident Hanoi into a violin, a “Hanolin” if you will…


| Voice ➝ Violin | |||
| Violin ➝ Flute | |||
| Mbira (Zimbabwe) ➝ Violin, Flute, Salo (Northern Thailand) | |||
| Listen to more audio examples here 🎵. | |||
As seen in the diagram below, we use the DDSP elements as the final output layer of an autoencoder. Whereas WaveNet and other neural audio synthesis models generate waveforms one sample at a time, DDSP passes parameters through known sound synthesis algorithms.
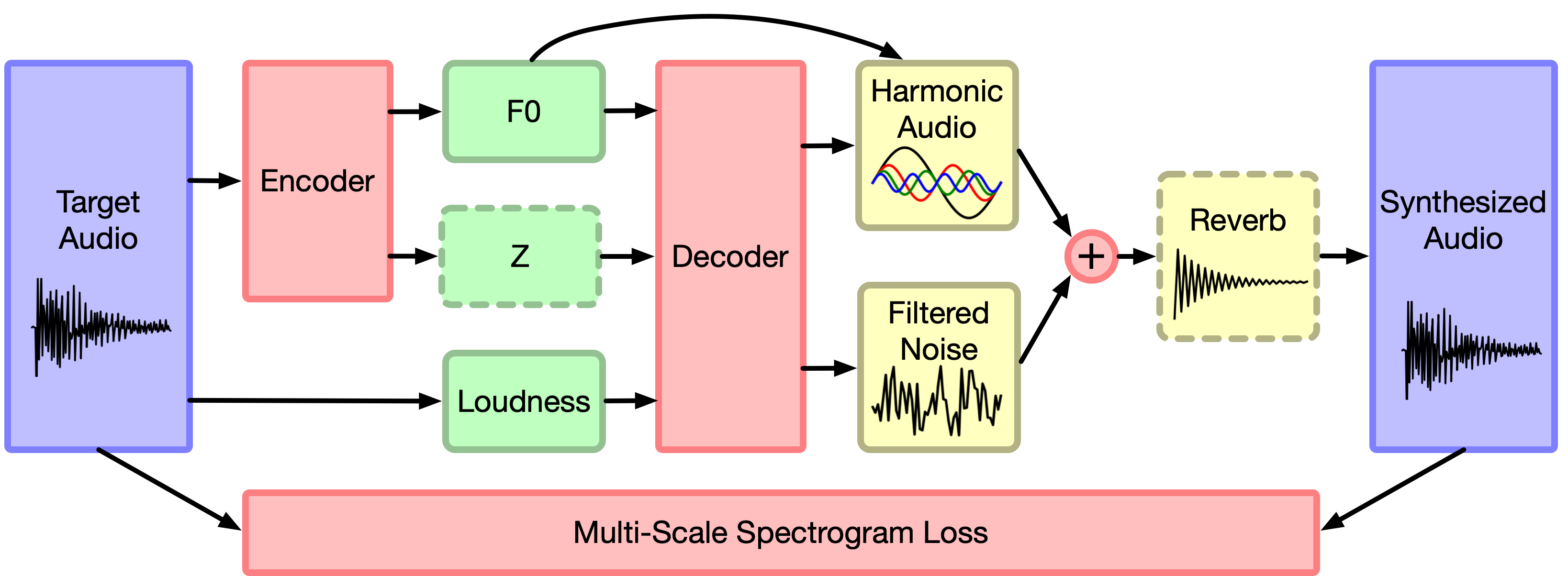
We combine a Harmonic Additive Synthesizer (that adds sinusoids at many different frequencies) with a Subtractive Noise Synthesizer (that filters white noise with time-varying filters). The signal from each synth is combined and run through a reverberation module to produce the final audio waveform. The loss is then computed by comparing spectrograms of the generated audio and source audio across six different frame sizes. Since all the components are differentiable, including the spectrograms, we can train the network end-to using backpropagation and stochastic gradient descent.
What’s next?
We’re really excited about all the potential applications for incorporating interpretable structure with deep learning, and think the current paper is just the tip of the iceberg. For instance, in addition to the processors in the paper, the library now has differentiable versions of Wavetable Synthesizers, Time-Varying Filters (like a neural wah-wah effect), Variable-Length Delay Modulation (like chorus, flanger, and vibrato effects), and two other parameterizations of Reverb. We’re also looking forward to seeing what others come up with! Granular Synthesizers? IIR filters? Physical Models? Your own personal favorite?
We have also worked hard to try and make the code as clean, tested, and understandable as possible (Check out the tutorial colab notebooks to learn more), and we would love your contributions!
How to cite
If you wish to cite this work, please use the paper where it was introduced:
@inproceedings{
engel2020ddsp,
title={DDSP: Differentiable Digital Signal Processing},
author={Jesse Engel and Lamtharn (Hanoi) Hantrakul and Chenjie Gu and Adam Roberts},
booktitle={International Conference on Learning Representations},
year={2020},
url={https://openreview.net/forum?id=B1x1ma4tDr}
}
Thanks to Monica Dinculescu for the awesome graphic, with icons from the Noun Project: Oscillator by James Christopher, Sound Wave by kiddo, Cat by parkjisun. Also thanks so much to Andy Coenen for the very sweet DDSP logo.