| 🎵Get the plugin |  Train your own model Train your own model |
Introduction
Back in 2020, we introduced DDSP as a new approach to realistic neural audio synthesis of musical instruments that combines the efficiency and interpretability of classical DSP elements (such as filters, oscillators, reverberation, etc.) with the expressivity of deep learning. Since then, we’ve been able to leverage DDSP’s efficiency to power a variety of educational and creative web experiences, such as Tone Transfer, Sounds of India, and Paint with Music. However, there’s one question we’ve received more than any other: “Nice! When can I get that plugin?”
We’re happy to announce that finally, now you can! Introducing DDSP-VST, a cross-platform real-time neural synthesizer and audio effect that you can run directly in your favorite digital audio workstation.
What can you do with DDSP-VST?
- Transform your voice or other sounds into a variety of musical instruments in effects mode
- Play neural synthesizers with MIDI just like a typical virtual instrument
- Explore wild and funky new timbres with intuitive tone shaping controls
- Train your own models for free with our web trainer, and share with your friends!
- Contribute your own cool features to the plugin (it’s open source!)
Why?
Our goal with Magenta has always been to go beyond the research papers to create tools that help artists and musicians explore the future of Machine Learning and Creativity. The research into DDSP was inspired by the challenge of making neural audio synthesis more tangible and accessible for everyone.
With DDSP-VST we hope to make it easy for anyone to not only use neural synthesizers in their music, but to also empower anyone to “get behind the steering wheel” and train and share their own models. Machine learning is infused with the bias of those who get to train the models, and we want to open that opportunity to more people to have their voices heard.
Using our accompanying web trainer, anyone can train a model for free with only a few minutes of audio training data.
How does it work?
DDSP-VST uses the same algorithm and operating principles as other DDSP applications before it, with some slight adjustments to improve efficiency for low-latency real-time audio. There are 3 stages to the plugin, each with their own unique set of controls
- Feature Extraction
- Predict DSP Controls
- Synthesis
Feature Extraction
The key to the plugin is that it represents incoming audio as just two signals: Pitch and Volume. The volume is just the RMS value of the incoming sound, and the pitch is extracted using a trained neural network.
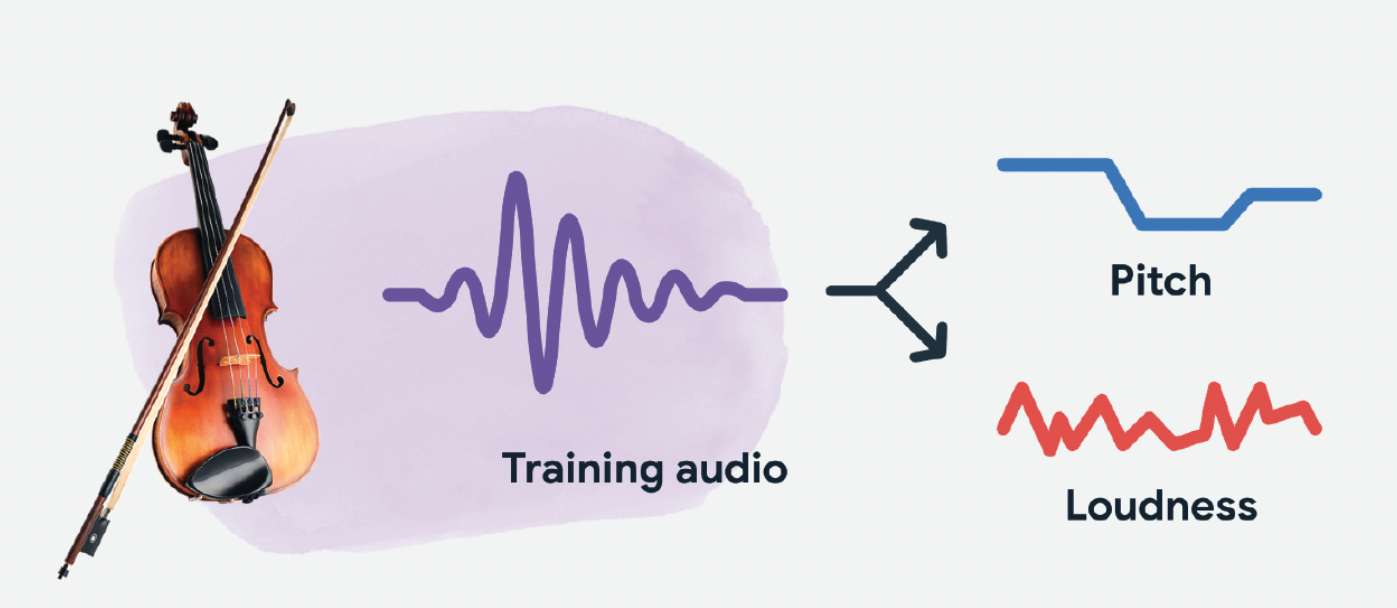
The original paper used a CREPE model for good accuracy, and our web application used a SPICE model for more efficiency. For the plugin, we pushed the efficiency even further by using network distillation to train a new tiny CREPE model that is close to the accuracy of the original with just ~160k parameters (137x less).
Predict DSP Controls
The second neural network predicts the controls for an additive harmonic synthesizer and a subtractive noise synthesizer for every pitch and loudness it receives. For efficiency, we trained a much smaller recurrent neural network (RNN) than the original paper, and found we could increase the time between predictions from 4ms to 20ms without much change in audio quality for a further 5x boost in efficiency. We also had to pay special attention to not incorporate any non-causal convolutions like the web versions of DDSP, as that would create latency from the model trying to “see into the future”.
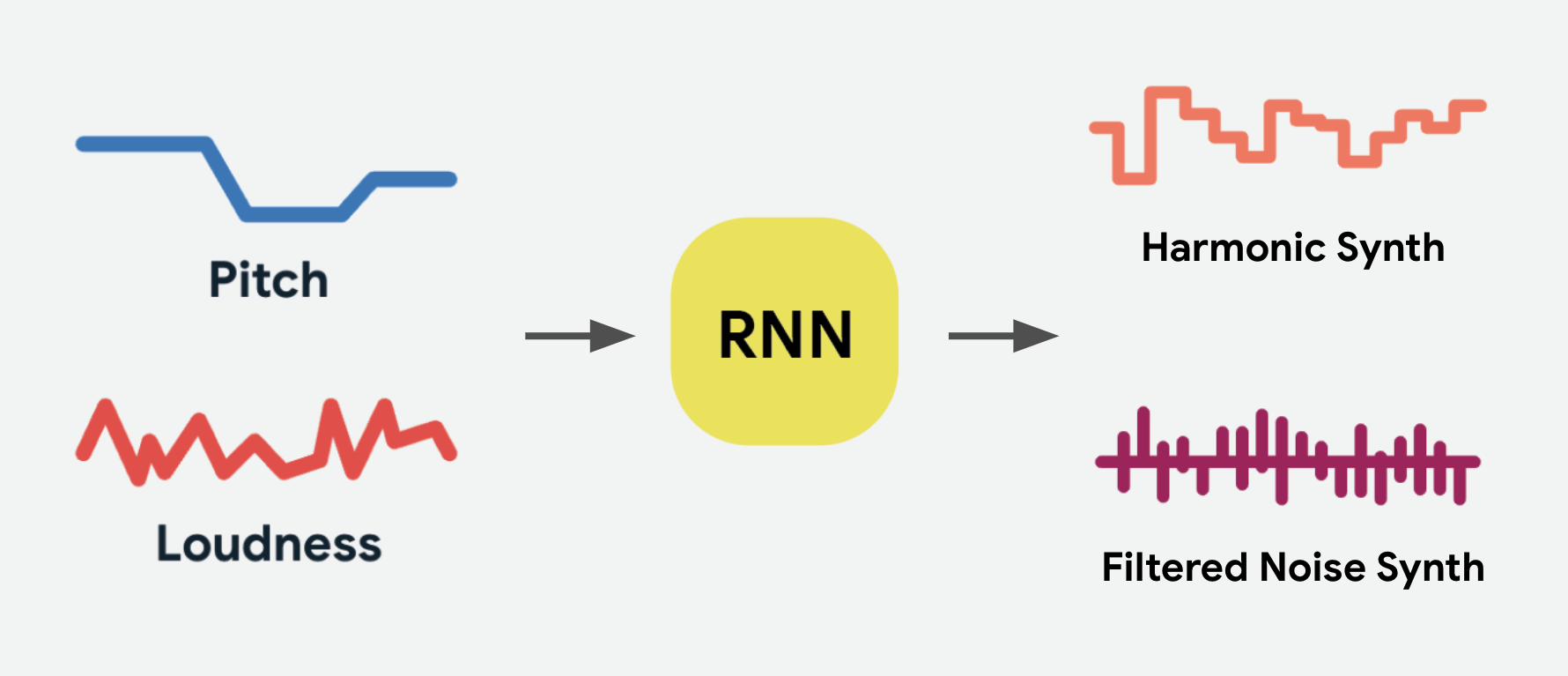
Synthesis
The outputs of these DSP synthesizers are then mixed together to produce the final audio output. In this way the RNN can take the volume and pitch from any input sound it wasn’t trained on and play the sound of the instrument it was trained on with the same volume and pitch contours.
Tone Shaping
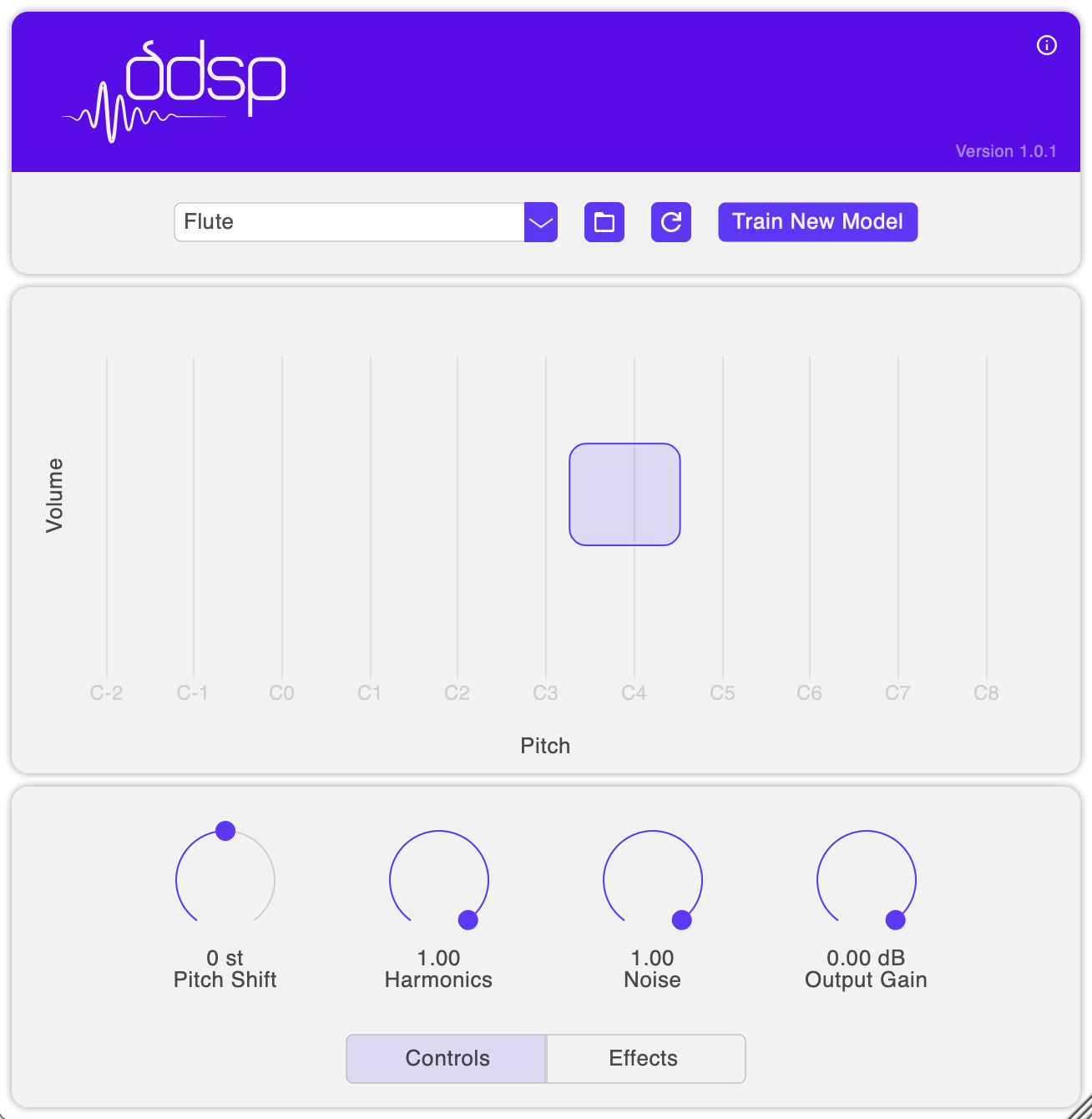
But, hold on… not all instruments can play all pitches. Flutes play high, basses play low–so, what happens if we feed in sounds with low pitches for a model trained on high pitches? We get some fun and wild new timbres!
Enter “Tone shaping” , a control that allows us to easily explore this space of sounds (and also get realistic sounds if that’s what we’re after). We can see our current volume and pitch by the bouncing purple ball. The range of volumes and pitches the model was trained on are shown by the highlighted box. When the ball is inside the box, we’re giving inputs like the training data so we get more realistic timbres. When it’s outside the box, we hear how the RNN predictions break down in fun and creative ways for values outside of training.
By allowing the box to be movable in both pitch and volume, we can shape the tone, to get wild variations of timbre, or get realistic tones by moving it to cover the ball. For the most realistic results, use the Pitch Shift knob to shift the input pitch into the original range of the box which is the original pitch range of the instrument (e.g. high for flutes, low for bass, etc.)
MIDI Synthesizer
We have also created a MIDI instrument version of the plugin, where pitch and volume contours are created directly from MIDI inputs. This enables using sequences, keyboards, arpeggiators, and other MIDI sources/effects to drive the plugin, and for neural synthesis to fit into existing workflows. It also avoids any pitch detection errors from the tiny CREPE model, for a more polished sound.
Train your own
One of our guiding goals has always been to democratize machine learning for artists and musicians, empowering creatives to decide for themselves how to use this new technology in their creative process. This allows for more diversity and control from practitioners and less constraints and bias from researchers.
One of the biggest barriers has always been allowing creatives to train their own models, as the training process usually requires a lot of training data and computational power. DDSP overcomes these challenges with the built-in structure of the model. This enables anyone to train their own model with as little as a few minutes of audio and a couple hours on a free Colab GPU. We’ve even observed that training can be finished in less than an hour on Colab Pro accounts.
Try out the free web trainer to train your own models and share with your friends.
Contribute
We think this plugin offers new opportunities to engage with a community of creators and we’re excited to see what everyone does with it. Creating the plugin was a community effort, and we look forward to improving it together. If you’re a musician, please try it out and share your models and music and feedback. The code is also open source for those willing and able to improve the plugin itself. We hope this project can also serve as a helpful starting point for others looking to make their own plugins with embedded ML models.
Acknowledgements
This has truly been a “passion project” with many people contributing their free time and advice to help make it happen. We would especially like to thank Holly Herndon, Matt Dryhurst, Hannes Widmoser, Rigel Swavely, Chet Gnegy, and Georgi Marinov for all of their contributions, effort, and advice.