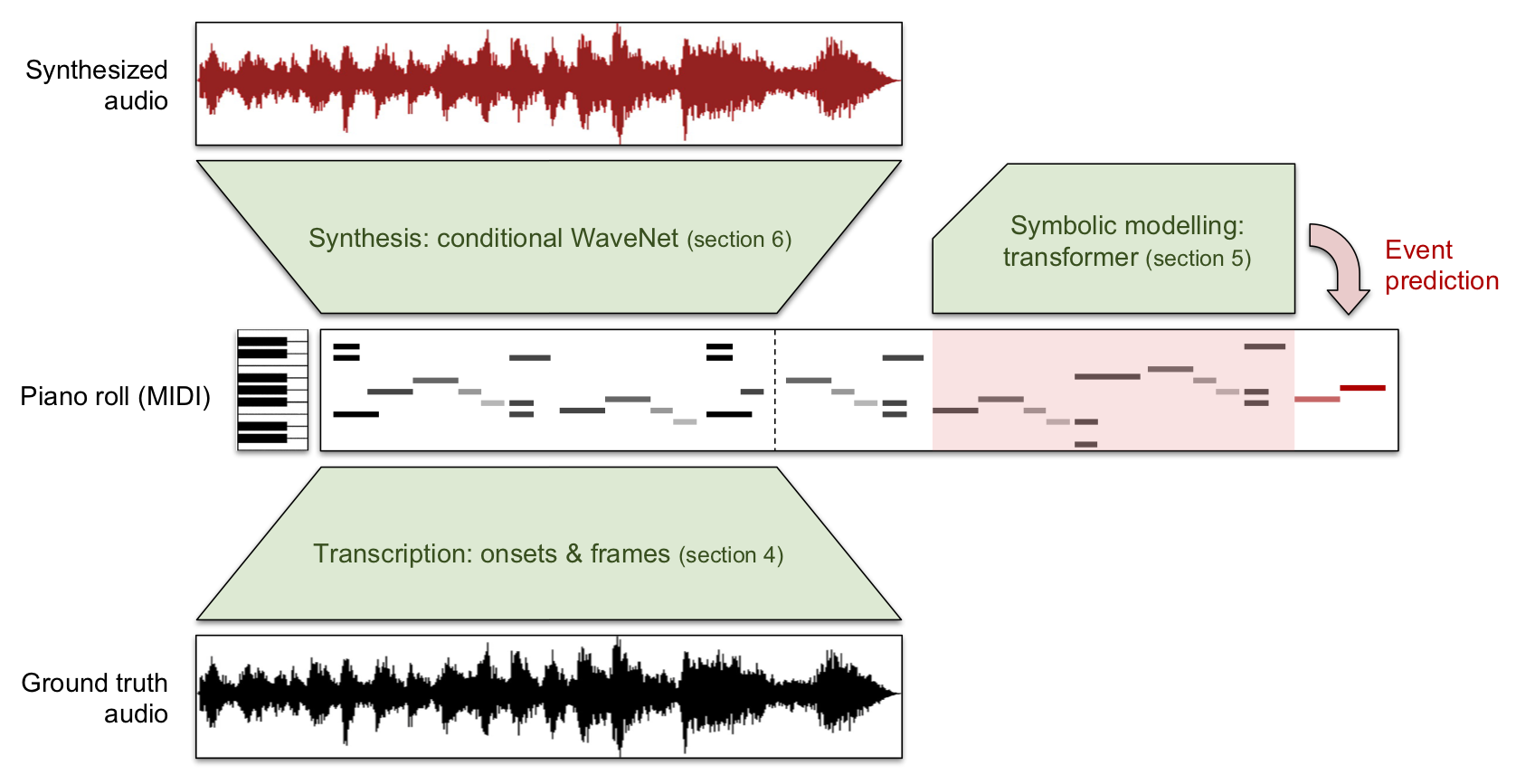
MAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) is a dataset composed of over 172 hours of virtuosic piano performances captured with fine alignment (~3 ms) between note labels and audio waveforms. This new dataset enables us to train a suite of models capable of transcribing, composing, and synthesizing audio waveforms with coherent musical structure on timescales spanning six orders of magnitude (~0.1 ms to ~100 s), a process we call Wave2Midi2Wave.
Here’s an excerpt of music composed by a Music Transformer model by Huang et al. trained on MIDI data transcribed from the piano audio in the dataset and then synthesized using a WaveNet model also trained using MAESTRO.
We are making MAESTRO available under a Creative Commons Attribution Non-Commercial Share-Alike license. More information and download links are on the MAESTRO dataset webpage.
Full details about the dataset and our Wave2Midi2Wave process are available in our paper: Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset.
Dataset
The MAESTRO dataset is based on recordings from the International Piano-e-Competition, a piano performance competition where virtuoso pianists perform on Yamaha Disklaviers with an integrated MIDI capture system. While several datasets of paired piano audio and MIDI have been published previously and have enabled significant advances in automatic piano transcription and related topics, we are making MAESTRO available because we believe it provides several advantages over existing datasets. In particular, MAESTRO contains over 172 hours of paired audio and MIDI recordings from nine years of the competition, significantly more data than similar datasets.
| Dataset | Duration (Hours) |
| MusicNet (piano only) | 15.3 |
| MAPS (Disklavier only) | 17.9 |
| MAESTRO | 172.3 |
The MIDI data includes key strike velocities and sustain pedal positions and is aligned to the audio with ~3 ms accuracy. Full details on the dataset, including our MIDI/audio alignment process, are available in our arXiv paper.
Transcription
Training our Onsets and Frames piano transcription model (with some modifications) on this dataset has resulted in a new state of the art score when evaluated against the MAPS Disklavier recordings. This is the Wave2Midi portion of Wave2Midi2Wave.
| Model | Transcription F1 score (0–100) |
| Onsets and Frames trained on MAPS | 50.22 |
| Onsets and Frames trained on MAESTRO | 67.43 |
More metrics and details available in our paper.
Music Transformer
Transcribing piano music allows us to work with it in a symbolic form, which is both easier for training generative models and for human manipulation. To demonstrate this ability, we trained a Music Transformer model on the transcriptions of the piano music and then used it to generate new piano performances. You could also train the Music Transformer on the ground truth labels, but training on the transcriptions demonstrates the possibility of training on new unlabeled collections of piano audio when paired with the transcription model above. This is the Midi portion of Wave2Midi2Wave.
Full details on Music Transformer training are available in our paper.
Synthesis
The high quality and size of the MAESTRO dataset also enables us to train a WaveNet model to synthesize realistic piano audio conditioned on MIDI input. Thanks to the accuracy of our transcription model, we could do this even for a collection of piano recordings for which ground truth is not available (though for these examples, we’ll continue to use the MAESTRO dataset). The generated piano audio sounds realistic and even retains characteristics of the source piano and recording environment. This is the Midi2Wave portion of Wave2Midi2Wave.
Here’s the same sequence as above, but synthesized using our WaveNet model.
As a fun side-effect, we are also able to alter performances and resynthesize with a different / more natural sound than other traditional signal processing techniques. For example, here’s a sample from Prelude and Fugue in A Minor, WTC I, BWV 865 by Bach with its tempo reduced by 50%. In the first audio clip, we modified the MIDI and resynthesized with WaveNet. The second was produced by modifying the audio with Ableton Live. Notice that the resynthesis method does not have the same artifacts as when modifying the audio directly.
One issue we found with the synthesis is that longer samples often have timbral shifts due to variation in recording settings in the ground truth data. By training with a conditioning signal for the year of the recording, we can force the model to generate with a single timbre over long time scales.
For example, this WaveNet synthesis of Prelude and Fugue in A Minor, WTC I, BWV 865 by Johann Sebastian Bach includes a timbral shift at time 0:34:
Here are some examples of the same piece synthesized with different year embeddings.
Conclusion
This Wave2Midi2Wave process is just one example of what is possible with the MAESTRO dataset. We look forward to hearing from you about what other uses you come up with for it!
Additional Resources
- Read technical details about the dataset and models in our arXiv paper.
- Listen to more examples from the paper.
- Download the dataset.