We’re excited to share Magenta RealTime 2 (MRT2), a state-of-the-art open model and efficient real-time inference engine that enables you to build and play AI musical instruments on your laptop!
To get started, download the apps on your MacBook (requires Apple Silicon).
Unlike other large generative music models that work offline to turn a prompt into a track, MRT2 is a live, interactive model that you can control with MIDI and audio, in addition to text. It performs low-latency on-device inference to respond to your inputs instantly. You can run it as a standalone app, drop it into your DAW, or integrate it into other music software.
In addition to the open-weights model, we are releasing a collection of playable instruments and experiences built with MRT2. Experiment with cloning sounds, blending styles, and creating live accompaniment with this low-latency music model.
To explore the potential of live music models as instruments, today we are releasing:
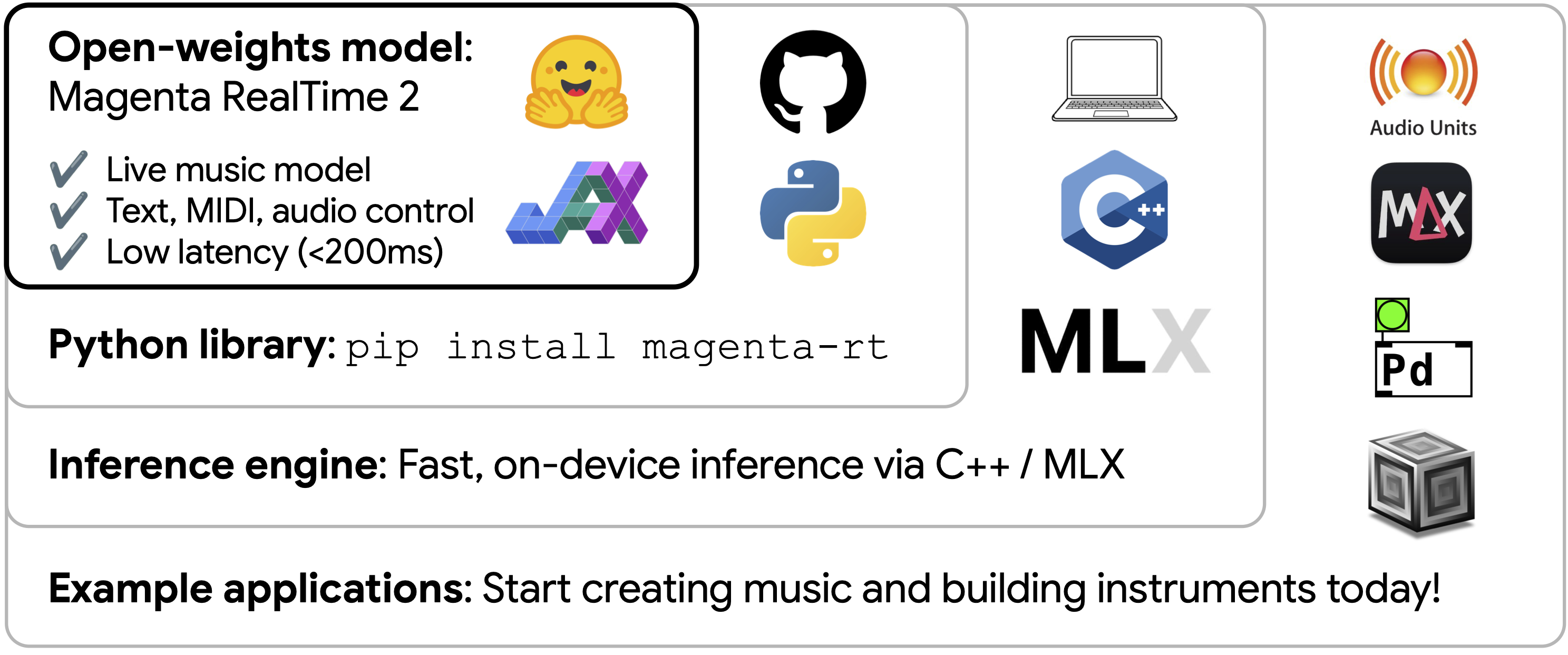
- Magenta RealTime 2, an open-weights model (2.4B parameters) capable of high-quality real-time music synthesis with low-latency real-time controls via MIDI, text, and audio.
- Alongside our model, we release an open source Python library (
pip install magenta-rt) offering inference via JAX/MLX using SequenceLayers. - An inference engine written in C++, enabling efficient streaming audio generation on a MacBook GPU via MLX.
- A suite of example applications built on the inference engine. These offer a glimpse into the creative potential of Magenta RealTime 2, and serve as references to help you get started building new instruments and software integrations.
For a decade, the Magenta team has championed a vision of AI as a tool for musicians, never a replacement. We released our first neural synthesizer, NSynth, back in 2017 which put machine learning into playable hardware. We continued creating AI Instruments with projects such as DDSP, Piano Genie, and the first version of Magenta RealTime, our debut live music model capable of generating and blending a wide range of musical styles. MRT2 achieves ~15x lower latency than version one, works on standard hardware and integrates directly into DAWs, making this live model a true musical instrument.
A live music model with lower latency and expanded control
| Magenta RealTime | Magenta RealTime 2 | |
| Live music generation | ✅ | ✅ |
| Hardware required | TPU/GPU | MacBook |
| Frame size | 2s | 40ms |
| Control latency | ~3s | ~200ms |
| Control modalities | Text, Audio | Text, Audio, MIDI |
| Model sizes | 760M / 220M | 2.4B / 230M |
Both MRT and MRT2 are codec language models operating on sequences of audio tokens from the SpectroStream codec, but MRT2 achieves lower latency by performing frame-level autoregression with frame-aligned conditioning. To enable expressive musical control, MRT2 is designed to model audio that continuously follows MIDI inputs, alongside style prompts which can be either audio or text; prompts are embedded via MusicCoCa. For minimal interaction lag, both signals are injected as frame-aligned conditioning at every generation step, allowing the model to react to changes in the signal within a single frame (40 ms, plus additional sources of empirical latency, see below).
Key to this approach is the use of a causal sliding window attention mechanism to enable continuous streaming generation while bounding memory requirements. Alongside this, learnable attention embeddings are also incorporated to improve generalization to arbitrary durations and context eviction artifacts (e.g., ringing and feedback) during long-context generation.
Fast C++ inference engine via MLX

While the original Magenta RealTime required a high-power GPU or TPU, Magenta RealTime 2 brings live generation to the hardware musicians actually use. To achieve this, we built a C++ inference engine powered by MLX that allows MRT2 to run natively on Apple Silicon. Apple’s MLX framework provides the link between Python and C++. More specifically, we use MLX to compile the MRT2 model, implemented using the SequenceLayers library, into an .mlxfn file which is a model container that bundles the weights and computational graph. Our C++ inference engine loads that file and uses the MLX runtime to efficiently execute it on Apple Silicon GPUs. The inference engine handles other necessary infrastructure (model state, audio buffering / resampling, MIDI input) and can be embedded into many music application frameworks where C++ supported.
MLX allows MRT2 to run on Apple Silicon (M-series): both model sizes can run offline (non-real-time) inference on any Apple Silicon Mac, while real-time streaming (generating audio faster than playback) is supported on the following devices:
| Model | Platform |
| Base (2.4B) | MacBook M3 Pro (or higher) MacBook M2 Max (or higher) |
| Small (230M) | Any Apple Silicon MacBook, including MacBook Air |
A suite of example applications for musicians and developers
A key goal of Magenta RealTime 2 is to allow musicians to integrate live music models within existing software, and help developers build custom applications. To help you get started, our codebase provides several examples, including standalone apps, plugins and extensions.
What’s Next?
Our team members have been building new instruments with machine learning for nearly 10 years, excitedly making unique and quirky sounds from statistical knowledge of music. With Magenta RealTime 2, AI instruments are finally starting to gain the controllability and immediacy we expect from music creation tools, but plenty remains to be explored. From even more interaction and lower control latency, to audio streaming inputs that can enable jamming and real-time audio control, we look forward to expanding the capabilities of live music models further. Stay tuned for future updates!
And in the meantime, we are also excited to bring more features and example applications to MRT2 soon, including:
- Finetuning, allowing anyone to customize the model by directly training on their own data.
- Example performance tools created in collaboration with Manaswi Mishra.
In the next few days, we will also be at the Music Technology Hackathon in Boston, where we are presenting a challenge centered around Magenta RealTime 2. We look forward to seeing what everyone will come up with!
Citation
Please cite our work as:
Magenta Team. “Magenta RealTime 2: Open & Local Live Music Models”. https://magenta.withgoogle.com/magenta-realtime-2. June 2026
@article{mrt2,
title = {Magenta RealTime 2: Open & Local Live Music Models},
author = {Magenta Team},
year = {2026},
note = {https://magenta.withgoogle.com/magenta-realtime-2}
}
Appendix: Technical Details
Low-latency streaming generation
Some background on Codec Language Modeling. A codec language model (LM) operates on discrete sequences of tokens from a neural audio codec. Here a codec refers to a pair of functions, an encoder and decoder, that convert audio to and from a discrete, compressed representation while minimizing distortion.
More formally, the encoder is a function mapping raw stereo audio waveforms \(\textbf{a} \in \mathbb{R}^{T f_s \times 2}\) into matrices of discrete tokens \(\mathbf{x} \in \mathbb{V}_c^{Tf_k \times d_c}\) where \(T\) is the duration in seconds, \(f_s\) the audio sampling rate, \(f_k\) the token frame rate, \(\mathbb{V}_c\) the codec vocabulary, and \(d_c\) is the number of tokens per frame. In this case, \(d_c\) refers to the “depth” of the residual vector quantization algorithm, referring to the iterative quantization of continuous embeddings of each audio frame.
The goal of the codec LM is to model these token matrices. For efficiency, an increasingly common approach is to adopt a hierarchical autoregressive framework using a pair of Transformers: one which compresses temporal history into fixed-length embedding vectors (\(\texttt{Temporal}_\theta\)), and another which iteratively decodes tokens depth-wise given the current frame embedding (\(\texttt{Depth}_\phi\)). Assuming \(\mathbf{x_i}\) refers to the \(i\)-th frame of \(\mathbf{x}\), and \(x_i^j\) refers to its \(j\)-th token, the joint distribution over \(x\) is modeled autoregressively as: \[ P_{\theta,\phi}(\mathbf{x}) = \prod_{i=1}^{Tf_k} \prod_{j=1}^{d_c} P_\phi(x_i^j | \mathbf{x_i^{<j}}, \texttt{Temporal}_{\theta}(\mathbf{x_{<i}})), \] where \(P_\phi(x_i^j \mid \cdot) = \texttt{SoftMax}(\texttt{Depth}_\phi(\cdot))\).
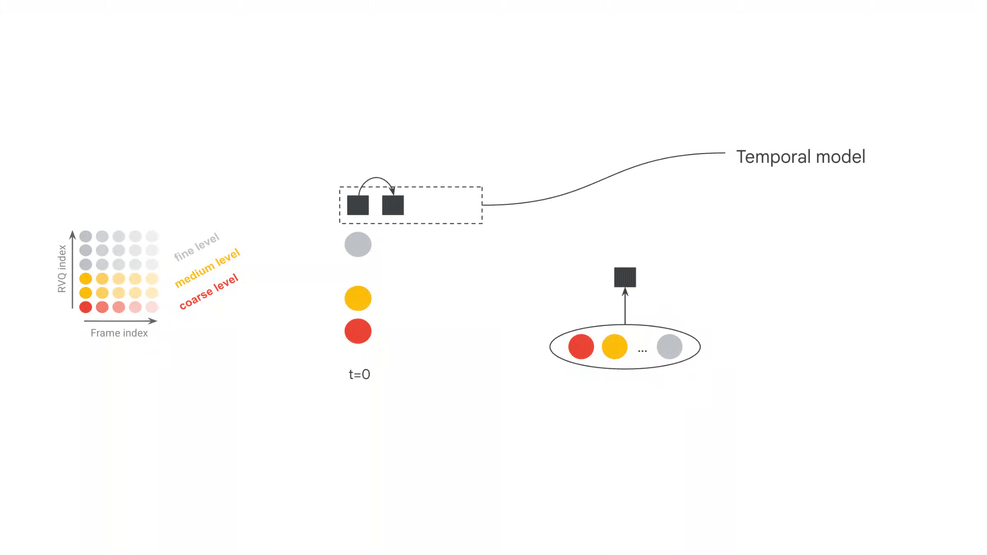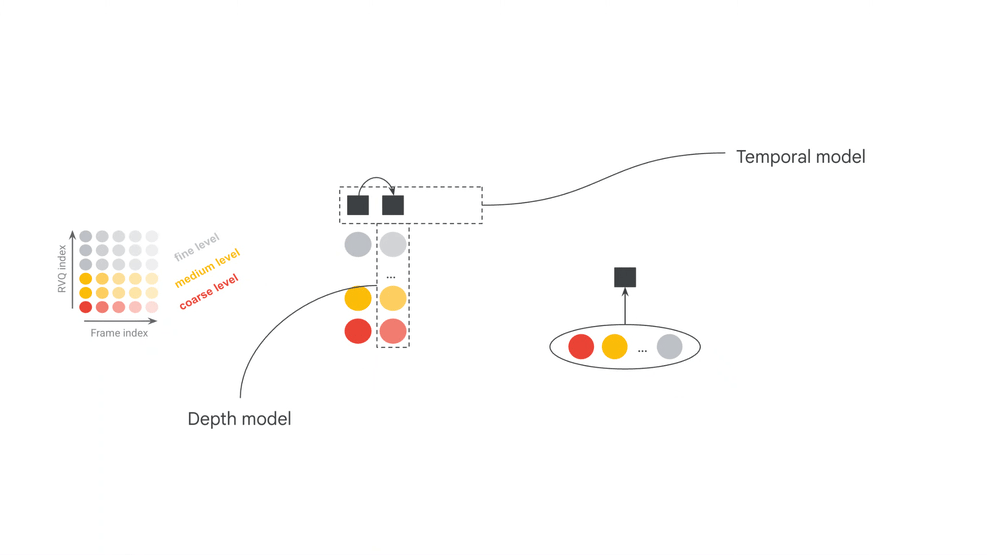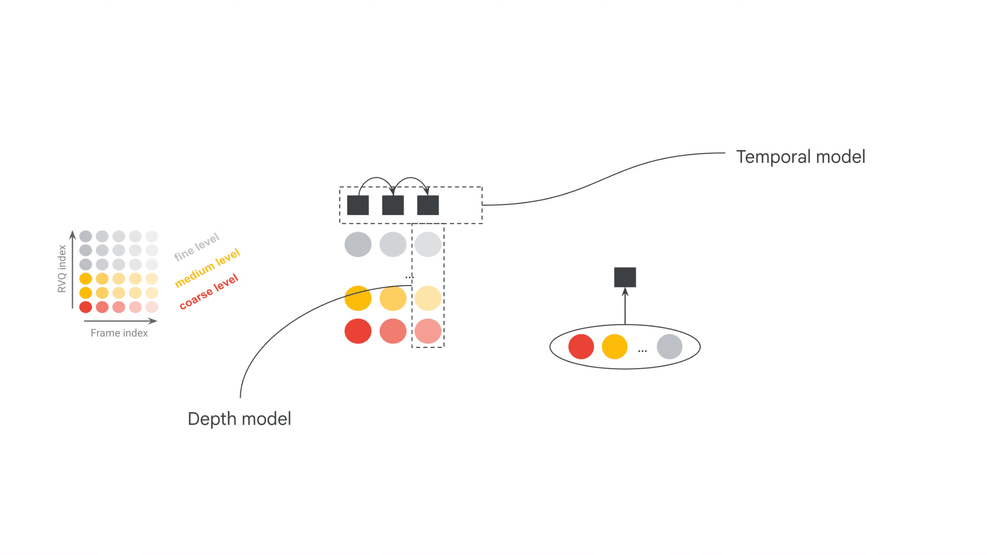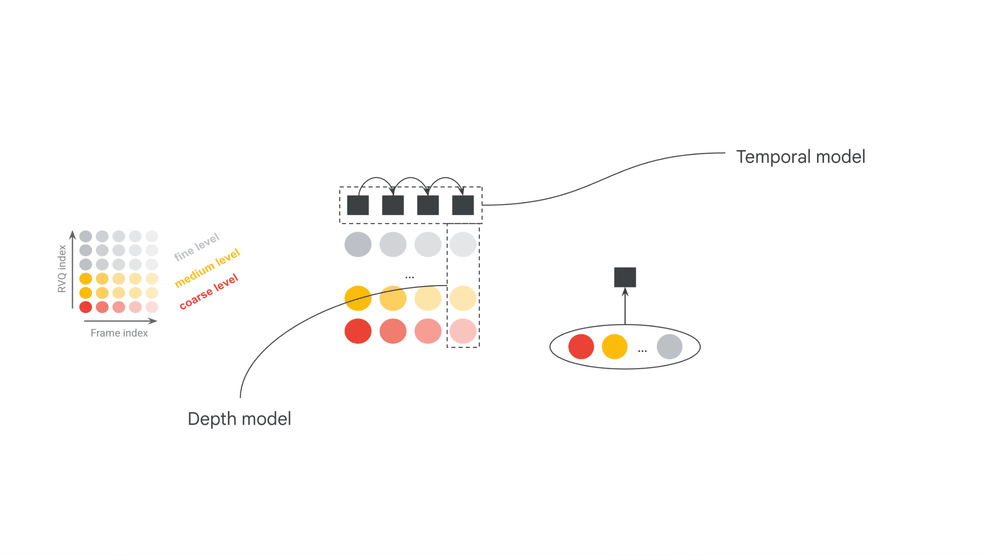
At inference time, we generate audio by first sampling a token sequence \(\mathbf{x’} \sim P_{\theta,\phi}(\mathbf{x})\) and then outputting \(\mathbf{a}’ = \texttt{Dec}(\mathbf{x}’)\), where \(\texttt{Dec}\) is the codec decoder. This describes our base modeling approach, shared with Magenta RealTime. For our codec, we use SpectroStream to compress high fidelity (\(f_s = 48\) kHz) stereo audio into tokens at \(3\) kbps (\(f_k = 25\) Hz, \(d_c = 12\), \(|\mathbb{V}_c| = 2^{10}\)).
Lowering autoregression granularity: from chunk to frame. To achieve streaming audio generation, we need to enforce two constraints:
- The system must generate at least \(f_k \cdot d_c\) tokens per second
- The decoder must be causal, meaning its output audio for frame \(i\) only depends on \(\mathbf{x_{\leq i}}\)
In the original Magenta RealTime, we satisfied requirement (1) by performing autoregression on chunks of frames, where each chunk is 2 seconds in duration. This design was chosen to amortize model runtime over chunk length to achieve real-time streaming. However, because the system must wait until the next chunk to inject any new user control information, the chunk duration creates a lower bound on control delay, resulting in a response time of 2 seconds at a minimum. Instead, Magenta RealTime 2 models individual frames, allowing us to reduce model response time significantly. To ensure continuous streaming generation while operating on single frames, we adopt a decoder-only architecture, using a local sliding window attention (SWA) in the temporal Transformer.
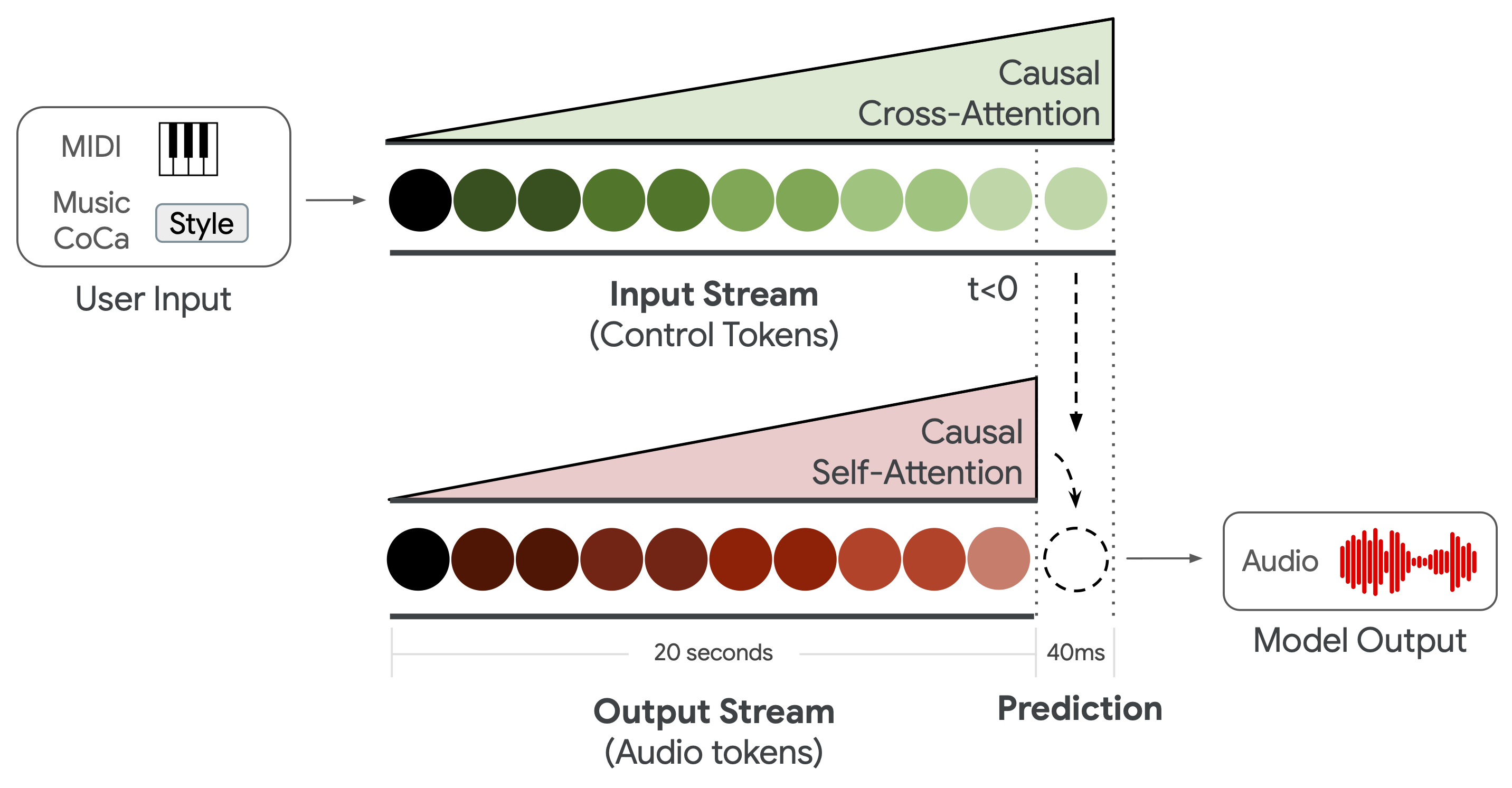
This has two key advantages: (1) the decoder-only architecture allows us to remove the sequential bottleneck introduced by the bidirectional encoder in Magenta RealTime, where the full encoder output has to be materialized before decoding can begin; (2) the rolling attention mechanism allows us to extend the context length while keeping the KV cache size fixed. At each step of the autoregressive generation, key-value entries for new tokens are written into the cache, and entries older than the window size w are evicted:
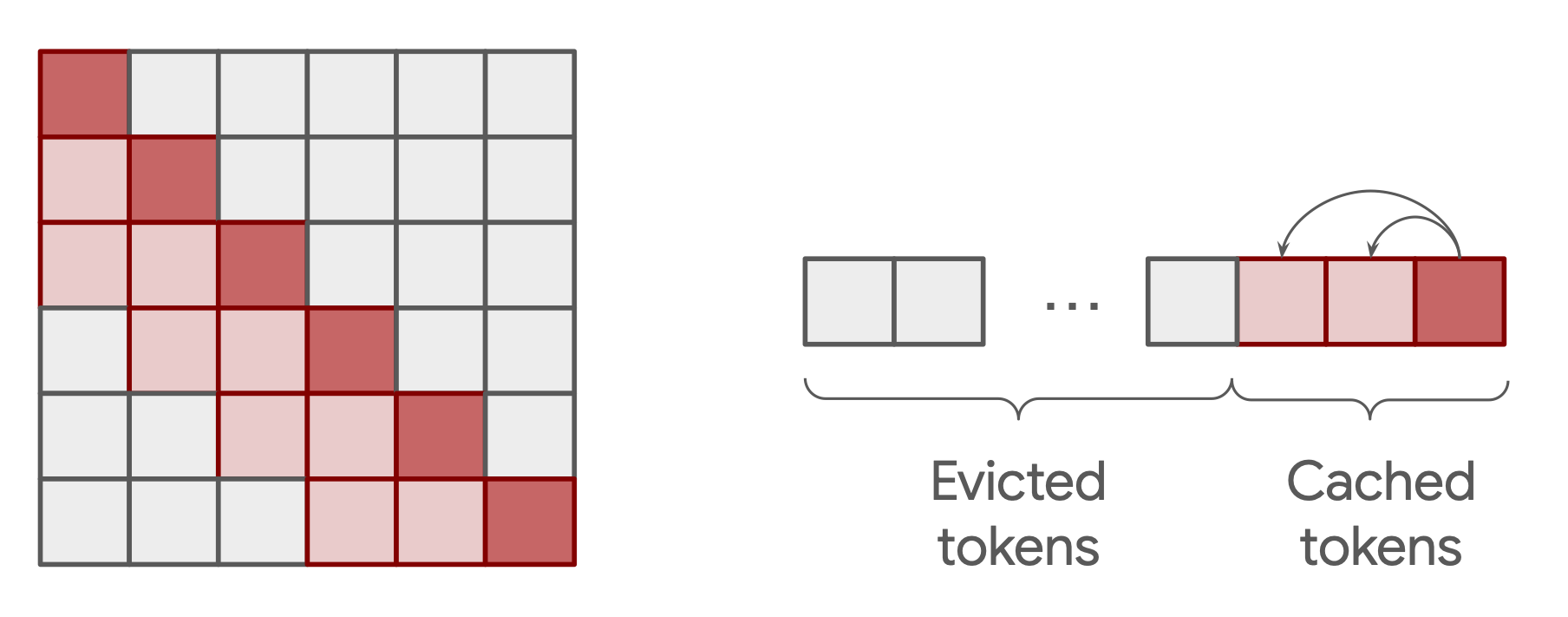
Similarly to previous work, we find that using a sliding window attention causes the model to significantly deteriorate when initial tokens are evicted from the cache. To remediate this, we make use of a learnable attention sink embedding. In order to reconcile the finite training length with the receptive field induced by the SWA mechanism, we also take care to set the attention window size such that this effective receptive field does not exceed the training crop length. Finally, we further reduce train/test mismatch and achieve better length generalization by dropping learnable positional embeddings (NoPE), after observing that RoPE hinders generalization beyond the training length. Instead, the model implicitly learns positional information by relying on causal masking and SWA, which naturally extend to arbitrary-length sequences without extrapolation issues.
Putting all this together, our model presents significant architectural differences compared to the previous version:
| Model | Magenta RealTime | Magenta RealTime 2 |
| Autoregressive unit | 2-second chunks (25 frames × 16 RVQ = 400 tokens) | Individual frames (12 RVQ tokens at 25 Hz = 40 ms) |
| Architecture | T5-style bidirectional encoder + causal decoder; encoder processes the full chunk of conditioning before decoding begins | Decoder-only; conditioning is injected at every frame, with no encoder forward pass as a sequential bottleneck |
| Minimum control delay | ≥ 2 s (next chunk boundary) |
~0.2 s (frame processing + depth decode + codec decode). See full latency diagram |
Precise control through frame-by-frame conditioning
A central feature of MRT2 is responsive, multi-signal control: in addition to style control expressed through audio or text, MRT2 also supports note and drums on/off control. This is achieved by modeling the conditional distribution \(P_{\theta,\phi}(\mathbf{x} | \mathbf{c})\), where \(\mathbf{c} = (\mathbf{c}_{style}, \mathbf{c}_{notes}, \mathbf{c}_{drums})\) is formed by tokenized representations of all conditioning signals at the audio frame rate (25 Hz), concatenated together into a single conditioning vector per frame. This vector is then mapped to a multi-channel embedding and injected into the temporal decoder through streaming cross-attention, enabling the model to react to changes in any signal within a single frame (~40 ms).
At inference we enable flexible joint guidance by extending the classifier-free guidance (CFG) approach in Magenta RealTime to multiple signals. This allows us to balance the contribution of each conditioning signal separately and according to the desired level of adherence, while also supporting unconditional generation for any subset of controls.
Style control through audio and text. Similarly to Magenta RealTime, MRT2 can also be steered through audio and text via quantized MusicCoCa embeddings. During training, we freeze the embeddings associated with the MusicCoCa tokens instead of learning them from scratch. The goal is to leverage the rich, pre-trained semantic representations coming from the Residual Vector Quantizer (RVQ). By keeping these embeddings frozen, we ensure the generative model receives stable semantic embeddings, which significantly improves prompt adherence at inference time. While MusicCoCa provides a joint embedding space between text and audio, the underlying distributions associated with both modalities do not match exactly. This creates a train-test mismatch during inference, as the model has only been trained on audio embeddings, but receives text embeddings during inference. To bridge this gap, we train a generative model from which we can sample diverse audio embeddings given an input text embedding, learning the one-to-many relationship between a single text prompt and multiple valid audio signals. To ensure high performance, we employ a pixel Mean Flow (pMF) formulation, enabling high-quality one-step inference. Finally, training this mapper module on a mix of short tags and long-form captions provides flexible style control, ranging from simple tag-style inputs to highly detailed text descriptions.
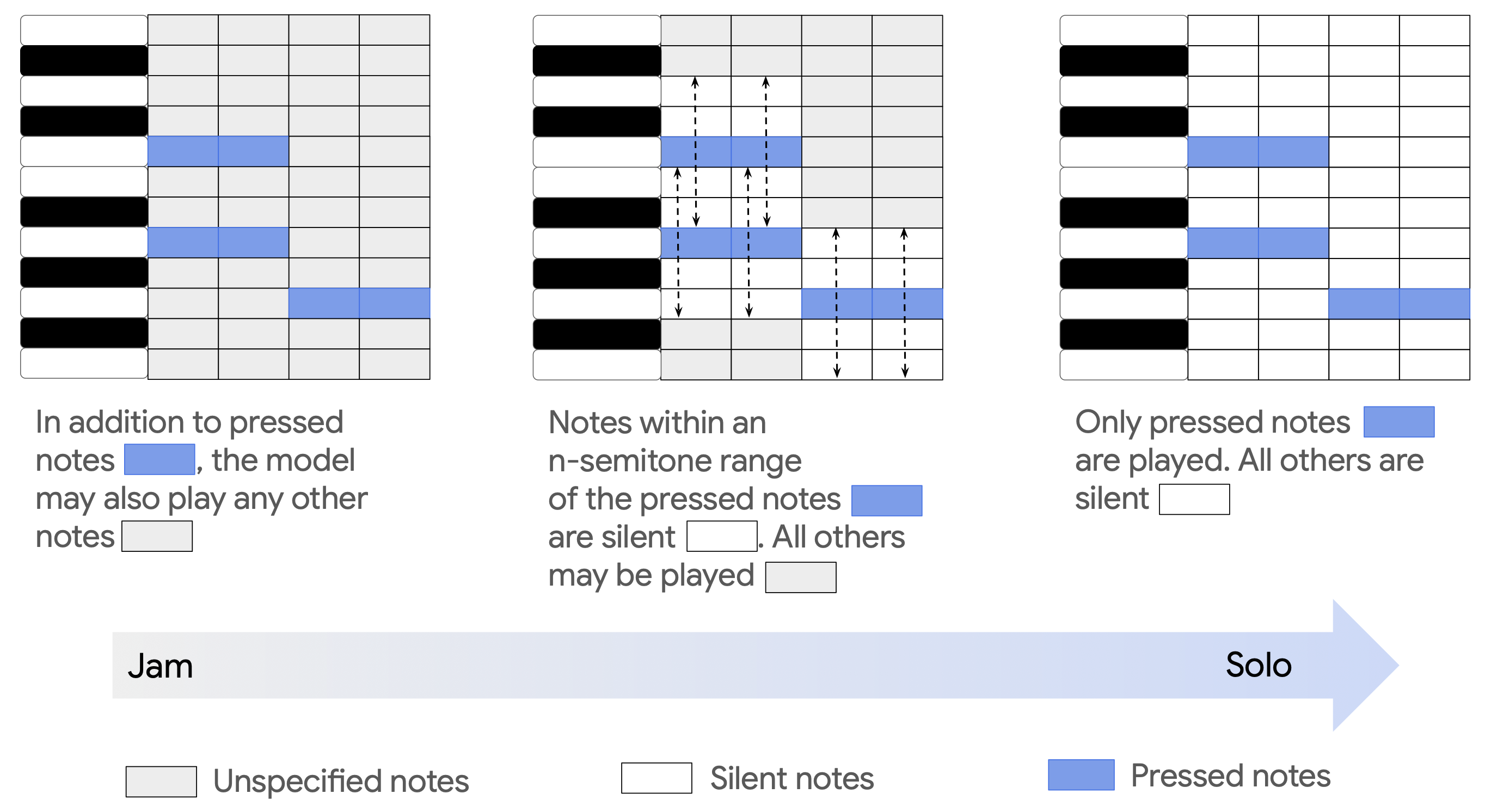
Note control. We enable note control by training on (audio, MIDI) pairs. Note activity is encoded as a 128-channel pianoroll – one channel per MIDI pitch – at the audio frame rate (25 Hz). The model is trained on around 71k hours of mostly instrumental stock music from a variety of sources, with MIDI labels inferred by the MT3 transcription model. We structure the per-pitch token vocabulary to support two control modes at inference. In Auto-Strum mode, the user specifies only which pitches are active at each frame, and the model determines where to place note onsets. In Auto-Strum OFF mode, the user can additionally specify the exact timing of each note onset, giving precise attack-level control. This is achieved through a 4-token vocabulary that distinguishes between note off, generic note on, note onset, and note continuation. When Auto-Strum is off, the model receives onset and continuation tokens directly, and respects the specified attack timing. When Auto-Strum is on, onset information is replaced with an onset mask token, and the model freely chooses when to place attacks based on the active pitch information alone. To support both modes with a single model, we employ onset masking, a training-time augmentation that stochastically replaces the onset and continuation tokens of randomly selected notes with the onset mask token. This trains the model to generate musically plausible attacks when no explicit onset information is present, while faithfully following onset cues when they are provided.
Drums on/off control. The note conditioning described so far gives us control over the melodic and harmonic content of the generated audio, but leaves us with no mechanism to control the presence of percussive elements. As a result, the model can arbitrarily include drums as part of the generated audio whenever this is admissible by the style conditioning (e.g. “jazz”). This can often be undesirable if, for example, the model is played alongside other instruments or as part of a multi-track session (e.g. in a DAW). For this reason, it’s useful to optionally switch off drum generation through an explicit control. We enable this through an additional conditioning signal: at training time, we pass a frame-wise sequence of drum hits obtained by transcribing drum stems from each training example using OaF Drums. While this trains the model to respond to drum hits, we find that direct drum control is infeasible in practice, given the end-to-end response time. Instead, we leverage this control purely for switching between drum-unconditional and drumless generation, using the same multi-guidance CFG as the other signals.
Inference-time masking as creative control. Beyond providing a set of control signals to guide generation, it is crucial to have a way to compose and modulate them. We accomplish this through selective input masking coupled with CFG scales, a technique that allows us to flexibly define playing modes at inference. More specifically, we introduce a masking scheme designed to accomplish two complementary goals: (1) strengthen the model’s ability to follow the controls while remaining robust to noisy or missing inputs, (2) enable partially unconditional generation as a form of creative control. During training, we stochastically mask contiguous regions of each conditioning signal independently, varying both the masking probability and spatial scale. We find that this results in better adherence to the inputs when they are specified. Importantly, this augmentation implicitly trains the model to interpret masked regions as unspecified, opening up a new dimension of creative interaction at inference. The Auto-Strum mode described above in the Note Control section is one such example. Similarly, we employ masking over the pitch dimension of the pianoroll to give the model more or less “creative freedom” over which pitches can be active. For example, masking all pianoroll pitches except those currently pressed allows the model to freely add harmonies or embellishments, while explicitly setting neighboring pitches to “off” (silent) constrains it to play only the input notes.
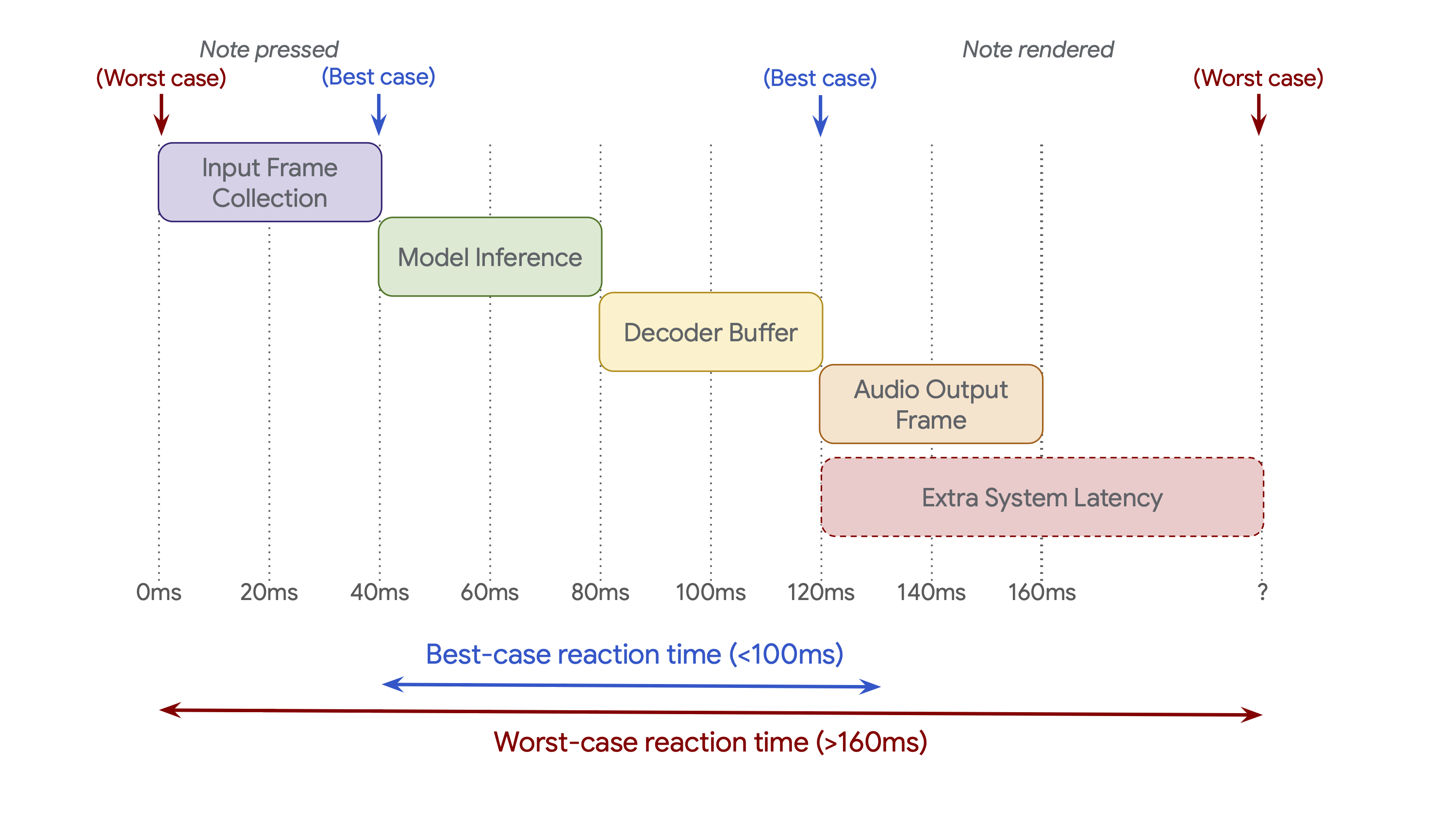
Real-world control latency. While we have significantly reduced the model frame size (from 2s to 40ms) compared to the previous generation, inference time isn’t the only source of latency. Below we give a sketch of end-to-end reaction time, taking into account input and output buffers, alongside additional sources of latency introduced by external components.