We are pleased to introduce MIDI-DDSP, an audio generation model that generates audio in a 3-level hierarchy (Notes, Performance, Synthesis) with detailed control at each level.
 Colab Demo Colab Demo |
🤗Spaces | 🎵Audio Examples | 📝ICLR Paper |  GitHub Code GitHub Code |
💻Shell Utility |
MIDI is a widely used digital music standard for creating music in live performances or recordings. It allows us to use notes and control signals to play synthesizers and samplers, for instance sending “note-on” and “note-off” information when pressing a key of a MIDI piano keyboard. While synthesizers can produce many sounds for each note, it is difficult to find control settings to produce realistic-sounding audio. On the other hand, samplers and black-box neural audio synthesis (e.g., WaveNet) can sound more realistic but offer less individual control.
Recently, we proposed DDSP, which combines DSP and neural networks to generate realistic audio with interpretable controls. While it’s fun to manipulate individual amplitudes and frequencies, these features are very low-level (250 times a second), so we wanted a way to also play DDSP models with more familiar note-level controls like MIDI.
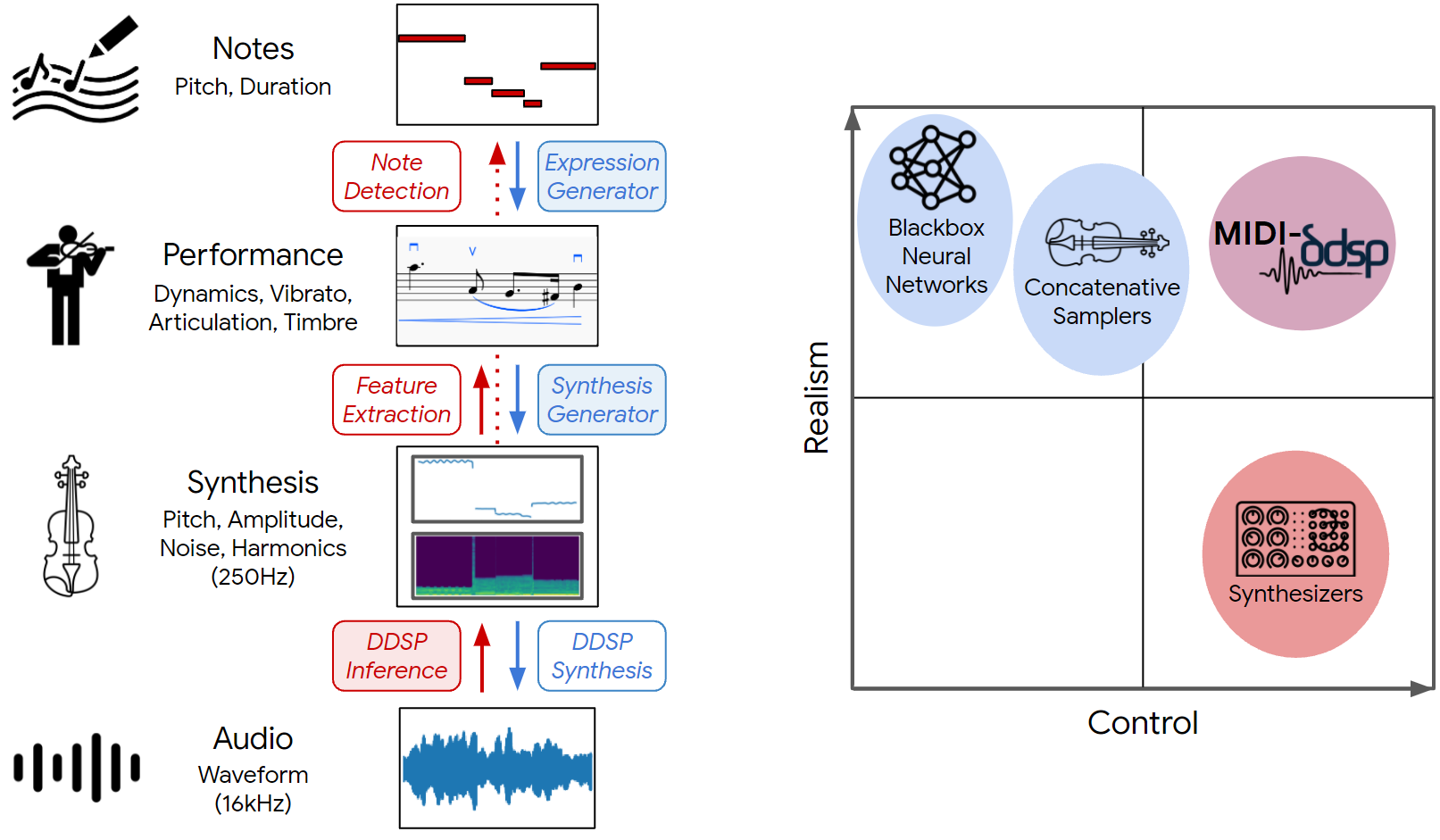
In this blog post, we introduce MIDI-DDSP, which leverages the expressive power of DDSP to create realistic-sounding audio, but also enables editing from slower input data like MIDI.
Specifically, MIDI-DDSP expands the DDSP synthesis into three levels: Note, Performance, and Synthesis, as shown in the figure above. These levels are designed to be analogous to how humans create music. Given a note sequence, we use an expression generator to predict the note-wise expression controls of each note. Then, we use a synthesis generator to predict per-frame synthesis parameters from note sequence and note expression controls. Last, DDSP synthesizes audio waveform from synthesis parameters. Each level is interpretable and able to be exposed to the user, such that they can make edits and change the output audio at the Note level, the Performance level, and the Synthesis level. See the figure below for an example of this.
Fine-grained Control
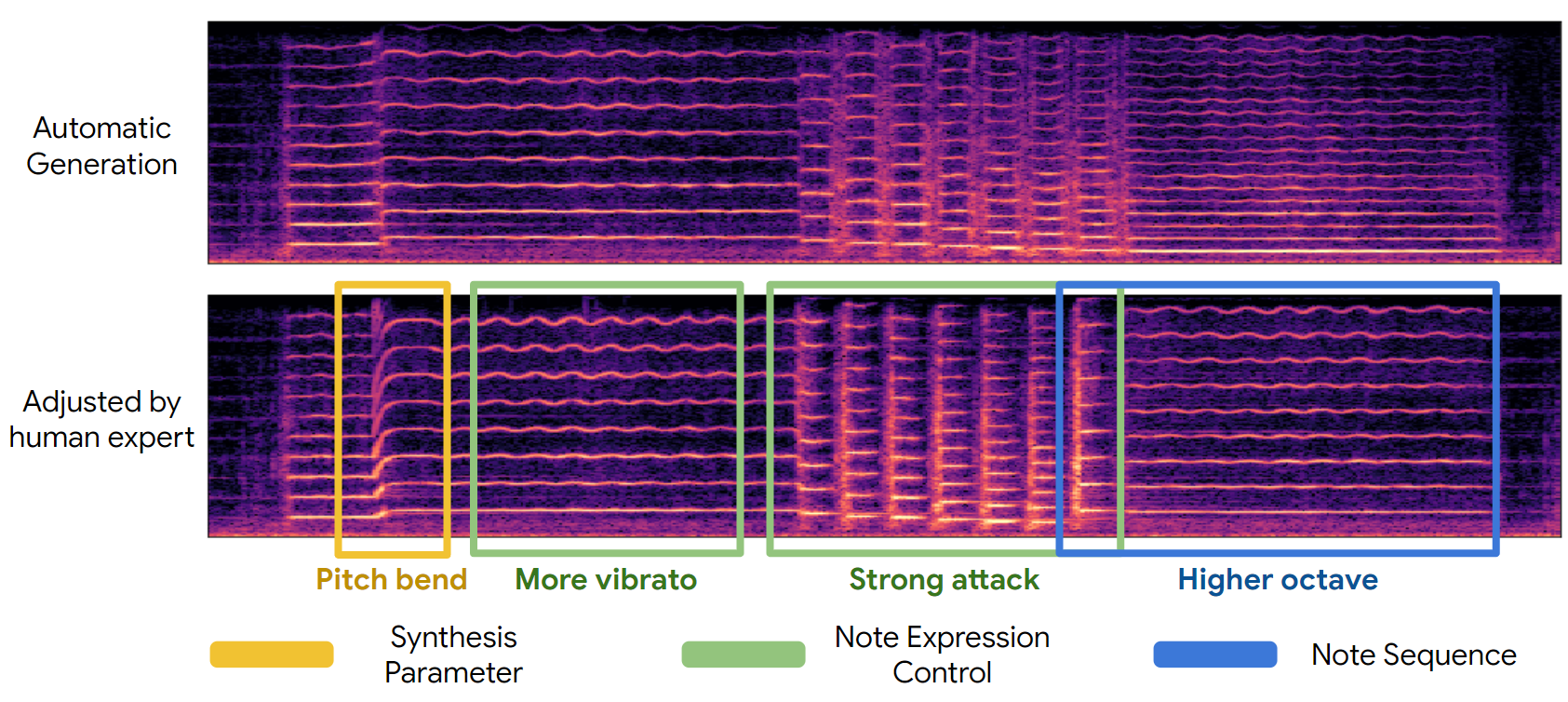
| Automatic Generation | Adjusted by Human Expert | ||
We define six note expression controls for each note. You can change the dynamics, pitch, and timbre of each note in a performance by adjusting those expression controls to craft your version of the musical piece.
Hierarchical Generation
MIDI-DDSP can take input from different sources (human or other models) by designing explicit latent representations at each level. A full hierarchical generative model for music can be constructed by connecting MIDI-DDSP with an automatic composition model. Here, we show MIDI-DDSP taking note input from CoCoCo, a score-level Bach composition interface (powered by Coconet, the ML model behind the Bach Doodle), and automatically synthesizing a Bach quartet by generating explicit latent for each level in the hierarchy.
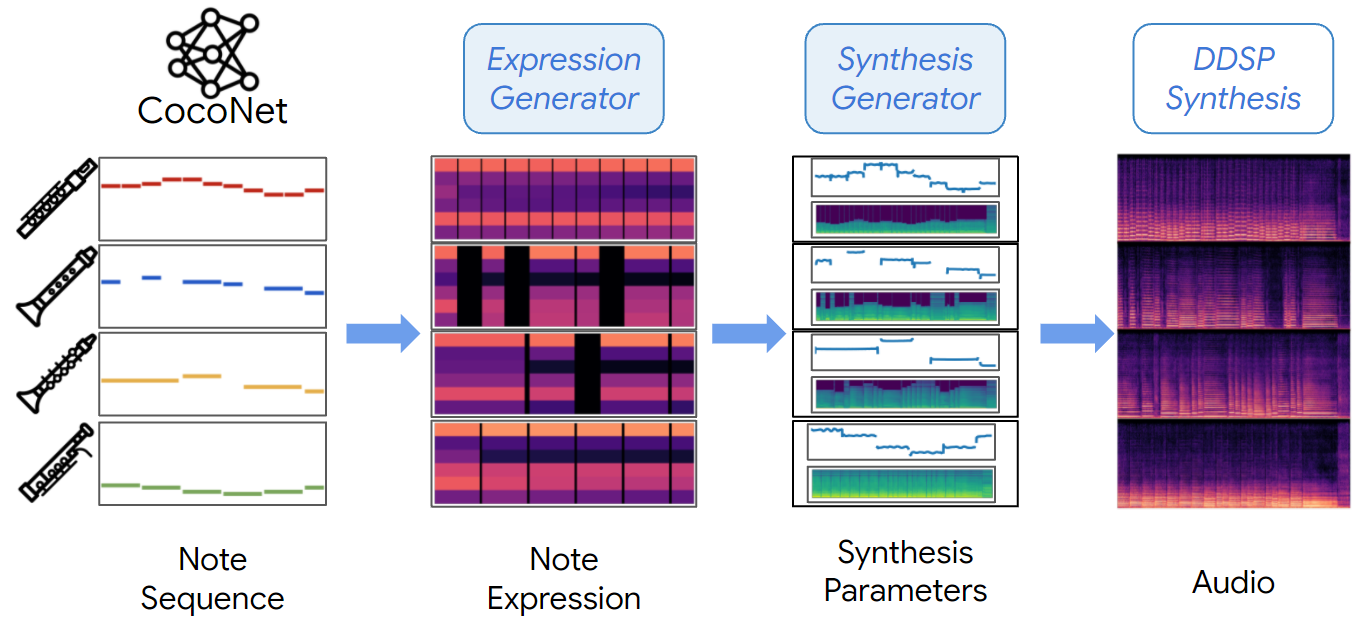
| Full end-to-end generation with Coconet (Mix) | |
| Soprano: Flute | Alto: Oboe |
| Tenor: Clarinet | Bass: Bassoon |
More Audio Samples
Here we present more audio samples that are automatically generated from MIDI-DDSP, some with human adjustments for refinement.
Automatic Generation
| Game of Thrones - Cello | BWV227.1 - String Quartet |
Human Adjustment - Pirates of the Caribbean
| Automatic Generation | Human Adjustment |
You can listen to more audio examples here 🎵.
We hope you have fun with MIDI-DDSP and you can try it yourself to render MIDI, and even adjust note expressions or synthesis parameters! We have open-sourced the code, and we provided a Colab notebook for MIDI synthesis and interactive control. If you want to synthesize MIDI files in command-lines just like using tools like FluidSynth, we also provide a command-line interface for synthesis.
@inproceedings{
wu2022midi,
title={MIDI-DDSP: Detailed Control of Musical Performance via Hierarchical Modeling},
author={Yusong Wu and Ethan Manilow and Yi Deng and Rigel Swavely and Kyle Kastner and Tim Cooijmans and Aaron Courville and Cheng-Zhi Anna Huang and Jesse Engel},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/pdf?id=UseMOjWENv}
}
Many thanks to AK for creating a 🤗 Space for the project!