One of the areas of interest for the Magenta project is to empower individual expression. But how do you personalize a machine learning model and make it your own?
Training your own model like Music Transformer, MusicVAE or SketchRNN from scratch requires lots of data (millions of data points), lots of compute power (on specialized hardware like GPUs/TPUs), and hyperparameter sorcery. What if you only have a laptop with a couple minutes of training data?
Without a lot of data, a model just memorizes the training data and doesn’t generalize to produce varied outputs – it would be like trying to learn all of music theory from a single song. Fine-tuning on a smaller dataset is a popular approach, but this still requires a lot of computation to modify the full network. However, since models like MusicVAE and SketchRNN learn a latent space, we can overcome this by training a separate “personalized” model to only generate from the parts of latent space we want.
Here, we introduce this approach to quickly train a small personalized model to control a larger pretrained latent variable model, based on prior work by Engel et al. To show its application for creative interactions, we implement this in TensorFlow.js as a standalone application, so that the model training happens in real-time, in a browser, closest to the end user. The model is also available in Magenta.js.
Constraining MusicVAE samples
MusicVAE is a hierarchical variational autoencoder that learns a summarized representation of musical qualities as a latent space. It encodes a musical sequence into a latent vector, which can then later be decoded back into a musical sequence. Because the latent vectors are regularized to be similar to a standard normal distribution, it is also possible to sample from the distribution of sequences, generating realistic music based on a random combination of qualities.
However, even though MusicVAE’s latent space is significantly smaller than the space of all possible note sequences, it was still trained to approximate many different melodies. This means that without knowing exactly which latent space a particular style or genre is encoded to, conditional sampling is not exactly possible. Even if you could encode a particular style to a latent vector, it’s hard to determine how to further modify each of the 256 dimensions to sample more melodies in that style.
To solve this, we train a smaller VAE on MusicVAE’s latent space. This smaller VAE (which we called “MidiMe”) learns a much smaller latent representation of the already encoded latent vectors. The intuition is that if 256 dimensions were enough to summarize the musical features of all training set melodies, then a much smaller number (like 4) can be enough to summarize the summarized musical feature of a particular melody. Visually, it looks like this:
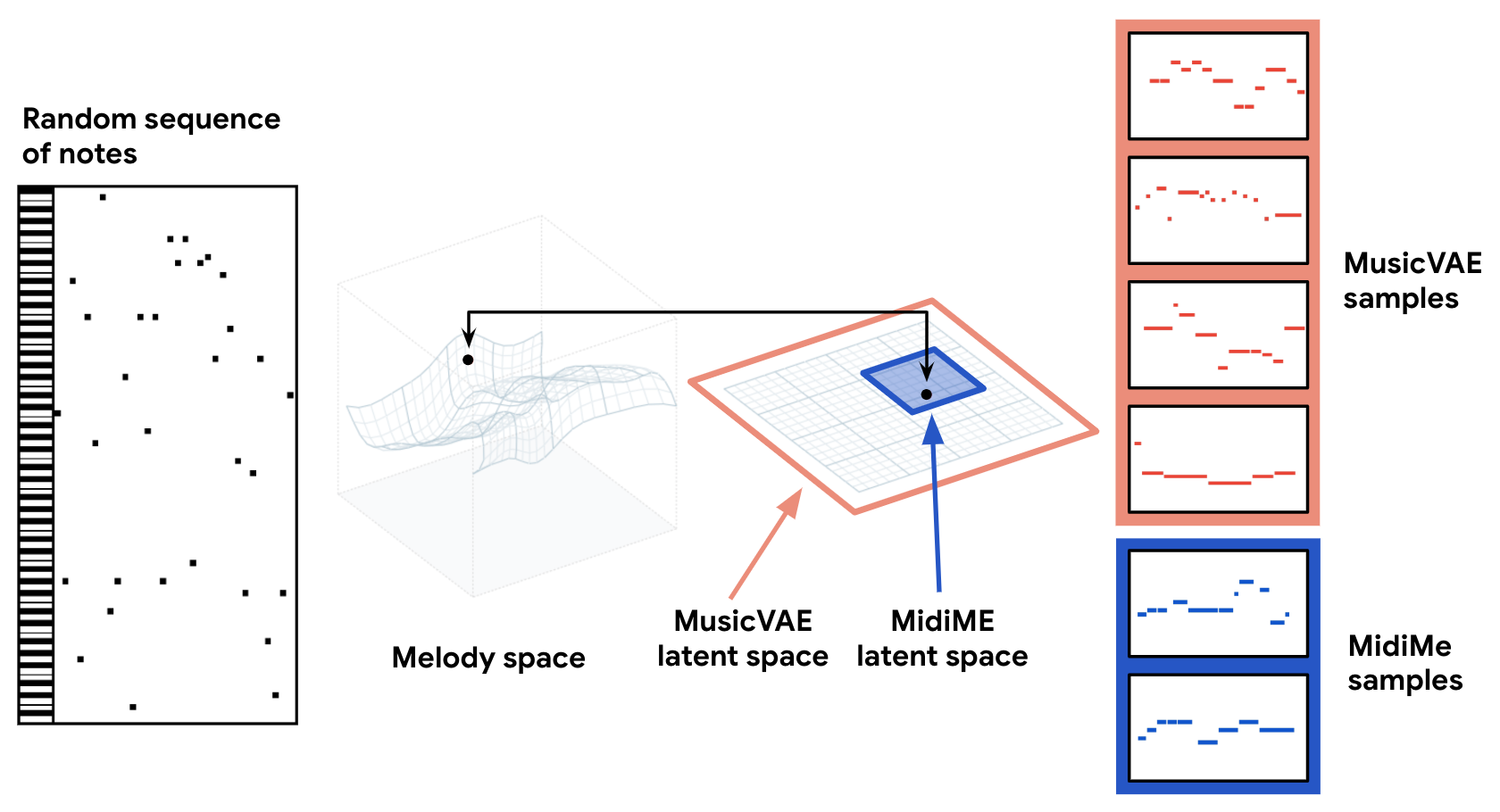
The MidiMe model needs a batch of MusicVAE latent vectors for training – in practice, this can be done by taking an existing MIDI file, splitting it up in chunks of the same size, and using these chunks as the batch. Since MidiMe learns a subset of an existing MusicVAE model, its reconstruction or generative qualities depend a lot on the kind of MusicVAE model you start with.
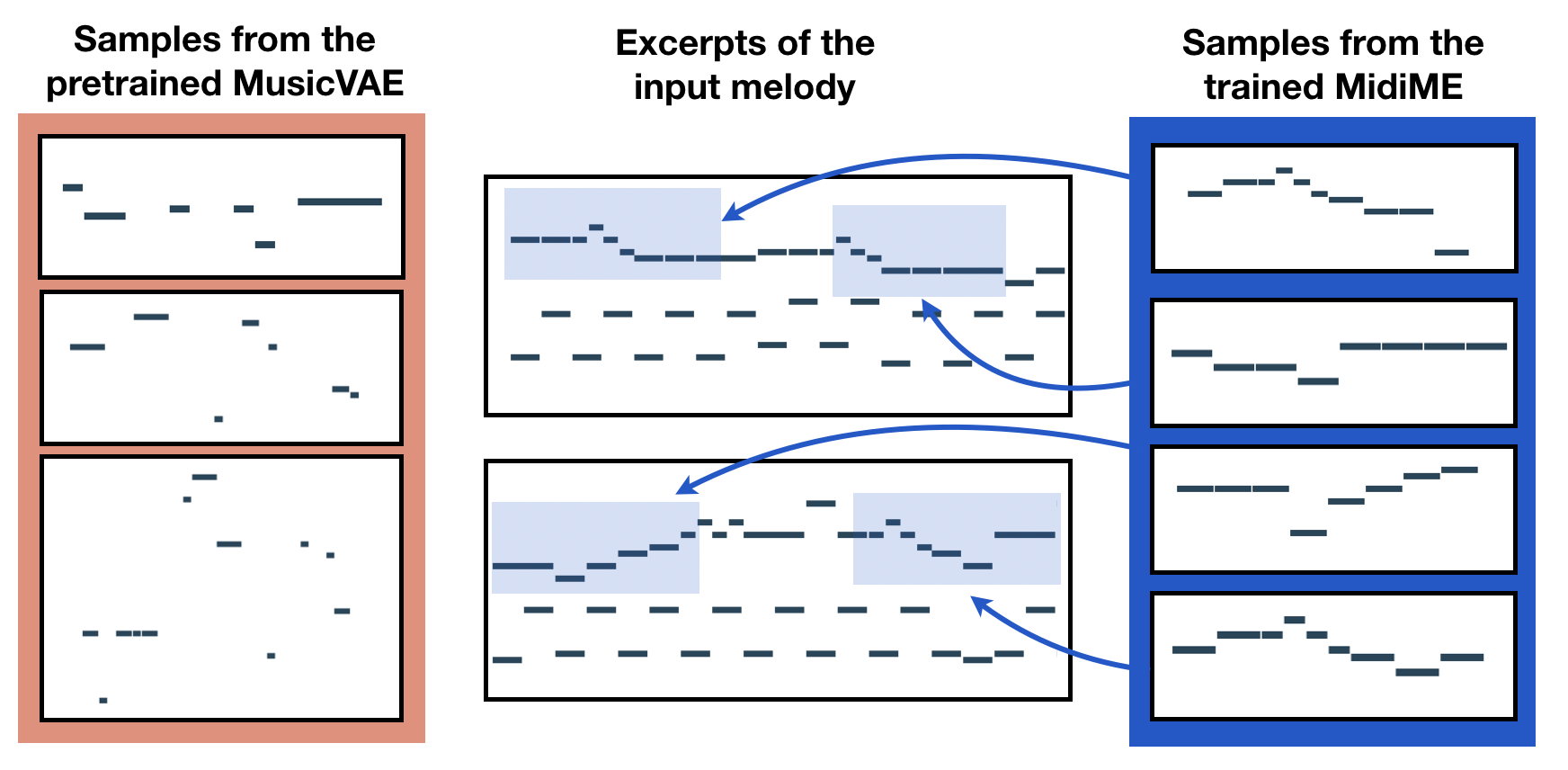
For example, a monophonic MusicVAE model might be very good at reconstructing the melody of an input. As a result, a MidiMe model trained on the latent vectors from that MusicVAE will also learn to reconstruct the training data very well, and most of its generated samples will sound very close to the training data. In the examples below, even though the input itself isn’t monophonic, since the MusicVAE latent vectors only encode the melody, the MidiMe model does a good job at summarizing those melody features. Each sample below is repeated twice, so that you can hear the difference more easily.
| Monophonic samples from MusicVAE |
|
|
| Single instrument, polyphonic MIDI melody (A traditional Christmas song) |
| Monophonic samples from MidiMe (trained on that song) |
|
|
In contrast, a polyphonic model like the MusicVAE trios model is optimized to generate very plausible samples, but not provide good reconstructions – the MidiMe model trained on this will generate samples that don’t sound identical to the training data, but have more motifs and musical patterns than the MusicVAE samples.
| Trio samples from MusicVAE |
|
|
| Polyphonic MIDI ("Deserve to be Loved" by Tanner Helland) |
| Trio samples from MidiMe (unlike the MusicVAE samples, the repetitive input melody line is preserved!) |
|
|
To see what this looks like yourself, we’ve built an app that lets you upload your own midi and train your own MidiMe model, in your browser:
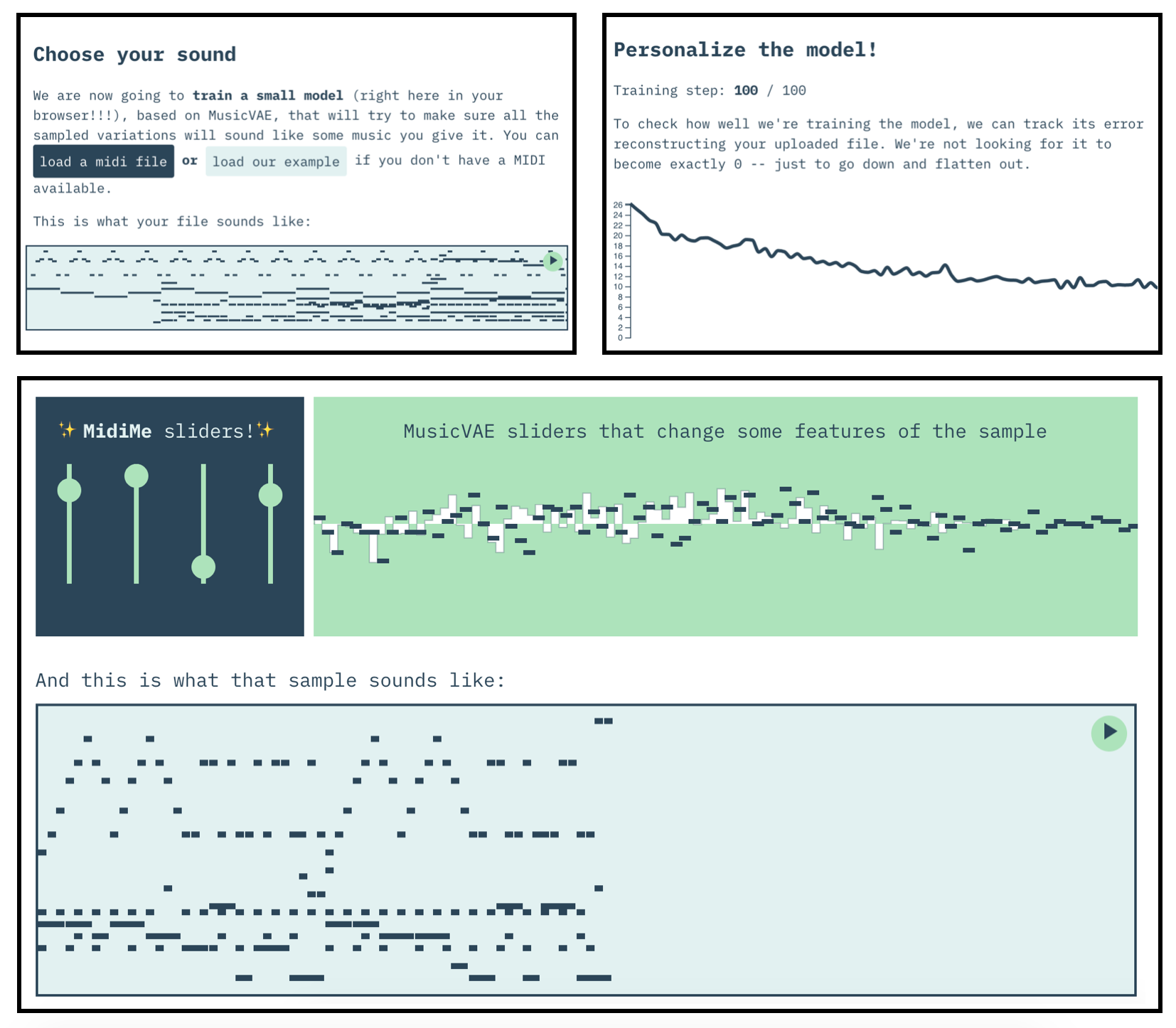
Prior Work
Latent Constraints
Personalization of generative models has always been a core interest of Magenta. In other words, we’re much more interested in letting an artist’s vision come through with custom machine learning tools than just imitating art and music that have already been made.
As we saw above, latent variable models offer one particular approach to customization. It is not the only way to customize a model (other approaches involve metalearning, fine-tuning, etc.), but it is uniquely data and compute efficient. This approach of learning to generate from a custom region of latent space can be thought of as applying a custom constraint to the latent space, or a Latent Constraint.
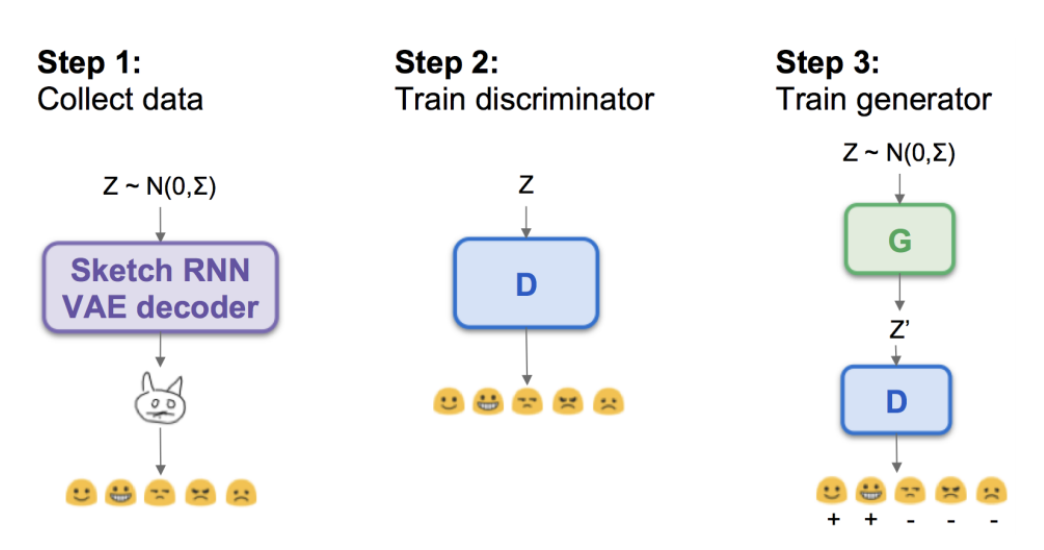
Latent Constraints were first introduced in the work of Engel et al. (Paper, Colab Notebook), by constraining the latent space of a VAE with a separate Generative Adversarial Network (GAN) trained in latent space. This is sometimes referred to as a LC-GAN. For example, you could take an unconditional sample of a VAE trained on the CelebA dataset, and constrain it to generate faces with certain attributes.

One cool aspect of this approach is that constraints could be applied without providing any data/labels, but only rules on the output. In the example below, you can see how the LC-GAN constrains a MusicVAE to only output music in a certain key (red notes are out of key) and with a certain density. The general contour of the original sample is maintained because the LC-GAN is trained to pick the closest point in latent space that satisfies the constraint.
| Prior sample |

|
| C Major Constraint |

|
| C Major + High Note Density Constraint |

|
Keep in mind this happens with a quick training (~100 iterations) after the main training, so anyone could provide their own rules for the model to follow.
Social Awareness
Jaques et al. (Paper) followed up on this work by incorporating implicit feedback preferences from users. They first showed a bunch of prior samples from SketchRNN to people to see which samples caused people to smile or laugh the most. Using those labels they then trained an LC-GAN to constrain generation to those regions of latent space and found the resulting samples also caused people to have more positive affective responses.
We can see this LC-GAN in practice, using the SketchRNN drawings. The first row of each section below is the prior, and the second row is the LC-GAN output. Notice how the model is biased towards drawing cats with big cute cat faces, crabs with tiny cute bodies, and just all-around better looking rhinos.

Latent Translation
LC-GAN is what we call an implicit latent constraint, because the model learns to implictly sample from the desired section of latent space without explicitly modeling the full density of that region of space. Using a VAE (LC-VAE) instead of a GAN would then be an explicit latent constraint. Tian et al. (Paper) applied this approach to learn to translate between the latent spaces of two different pretrained models. As shown below, by training a single shared LC-VAE on two pretrained models (in this case a MNIST VAE, and a spoken digit GAN), you can then transfer features between very different domains.
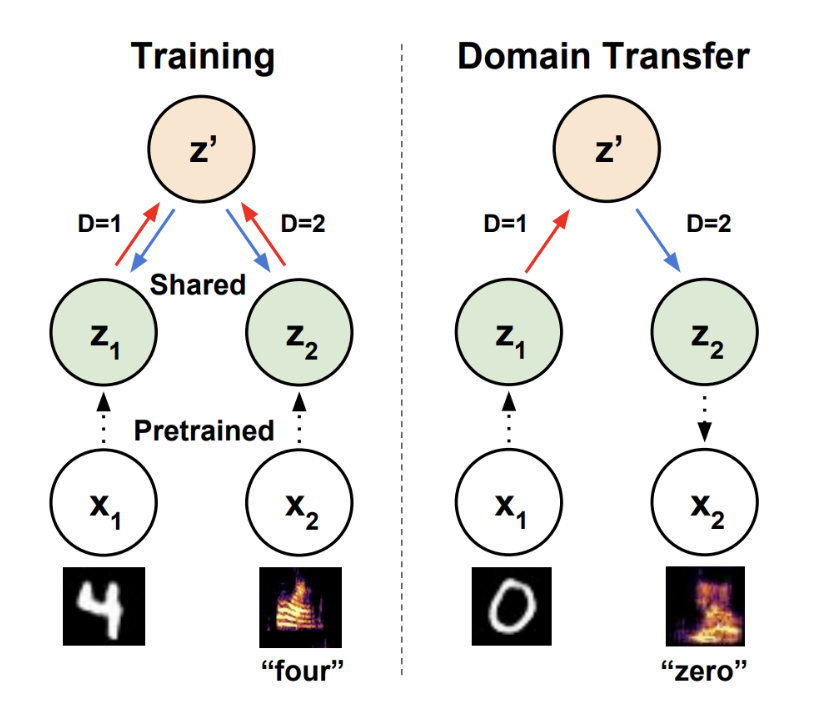
In the example below for transferring MNIST digits into Fashion-MNIST images, you can see that local similarities are preserved during the transfer process.

MidiMe
In the context of all that prior work, we can now see that MidiMe is just an LC-VAE applied to MusicVAE and trained on embeddings of data provided by you, to make your own custom MusicVAE.
Future Work
Latent constraints are just one approach to personalization, and indeed, many really interesting models don’t have latent variables to constrain (for example, Music Transformer). We’re excited by the future possibilities of enabling easy custom generative models, so stay tuned!
How to cite
If you extend or use this work, please cite the paper where it was introduced:
@proceedings{midime,
title = {MidiMe: Personalizing a MusicVAE model with user data},
editor = {Monica Dinculescu and Jesse Engel and Adam Roberts},
year = {2019},
booktitle = {Workshop on Machine Learning for Creativity and Design, NeurIPS}
}