When a painter creates a work of art, she first blends and explores color options on an artist’s palette before applying them to the canvas. This process is a creative act in its own right and has a profound effect on the final work.
Musicians and composers have mostly lacked a similar device for exploring and mixing musical ideas, but we are hoping to change that. Below we introduce MusicVAE, a machine learning model that lets us create palettes for blending and exploring musical scores.
As an example, listen to this gradual blending of 2 different melodies, A and B. We’ll explain how this morph was achieved throughout the post.
On the Magenta team, we often face conflicting desires: as researchers we want to push forward the boundaries of what is possible with machine learning, but as tool-makers, we want our models to be understandable and controllable by artists and musicians.
These desires have led us to focus much of our recent efforts on what are known as latent space models. The technical goal of this class of models is to represent the variation in a high-dimensional dataset using a lower-dimensional code, making it easier to explore and manipulate intuitive characteristics of the data. As a creative tool, the goal is to provide an intuitive palette with which a creator can explore and manipulate the elements of an artistic work.
Examples of latent space models we have developed include SketchRNN for sketches, NSynth for musical timbre, and now MusicVAE: a hierarchical recurrent variational autoencoder for learning latent spaces for musical scores.
In an effort to make it as easy as possible to build usable tools with MusicVAE, we are also releasing a JavaScript library and pre-trained models for doing inference in the browser.
Continue reading to learn more about this technology, or check out these additional resources:
- Read the technical details of the model architecture in our arXiv paper.
- Play with MusicVAE’s 2-bar models in your browser with Melody Mixer, Beat Blender, and Latent Loops.
- Learn how to use the JavaScript implementation in your own project with this tutorial.
- Sample and interpolate with all of our models in a Colab Notebook.
- View the Tensorflow and JavaScript implementations in our GitHub repository.
- Hear more examples in the paper’s online supplement and this YouTube playlist.
Latent Spaces
Musical sequences are fundamentally high dimensional. For example, consider the space of all possible monophonic piano melodies. At any given time, exactly one of the 88 keys can be pressed down or released, or the player may rest. We can represent this as 90 types of events (88 key presses, 1 release, 1 rest). If we ignore tempo and quantize time down to 16th notes, two measures (bars) of music in 4/4 time will have 9032 possible sequences. If we extend this to 16 bars, it will be 90256 possible sequences, which is many times greater than the number of atoms in the Universe!
Exploring melodies by enumerating all possible variations is not feasible, and would result in lots of unmusical sequences that essentially sound random. For example, here we show “pianorolls” of samples randomly chosen from the 9032 possible 2-bar sequences. The vertical axis represents the notes on the piano and the horizontal axis represents time in 16th note steps. We also include the synthesized audio for one of the samples.

Latent space models are capable of learning the fundamental characteristics of a training dataset and can therefore exclude these unconventional possibilities. Compare these random samples of points in a latent space of 2-bar melodies (described later in this post) to the previous ones:

Aside from excluding unrealistic examples, latent spaces are able to represent the variation of real data in a lower-dimensional space. This means that they can also reconstruct real examples with high accuracy. Furthermore, when compressing the space of the dataset, latent space models tend to organize it based on fundamental qualities, which clusters similar examples close together and lays out the variation along vectors defined by these qualities.
The desirable properties of a latent space can be summarized as follows:
- Expression: Any real example can be mapped to some point in the latent space and reconstructed from it.
- Realism: Any point in this space represents some realistic example, including ones not in the training set.
- Smoothness: Examples from nearby points in latent space have similar qualities to one another.
These properties are similar to an artist’s palette on which she can explore and blend color options for a painting, and much like a palette, these properties can enhance creativivty. For example, due to expression and smoothness, a latent space like the one learned by SketchRNN for sequences of pen strokes allows you to reconstruct and blend by interpolating between points in latent space:

Realism allows you to randomly sample new examples that are similar to those in your dataset by decoding from a randomly selected point in latent space. We demonstrated this above for melodies and do so here with SketchRNN:

We can also use the structure of the latent space to perform semantically meaningful transformations, such as with “latent constraints” or “attribute vector arithmetic”. The latter technique takes advantage of the fact that the latent space can “disentangle” the important qualities in the dataset. By averaging the latent vectors corresponding to a collection of datapoints which share a given quality (for example, sketches of cat faces), we obtain the attribute vector for that attribute (the “cat face vector”). By adding and subtracting various attribute vectors from the latent code and decoding with our model, we obtain an output with the relevant attributes added or removed. Again, we illustrate this with SketchRNN:
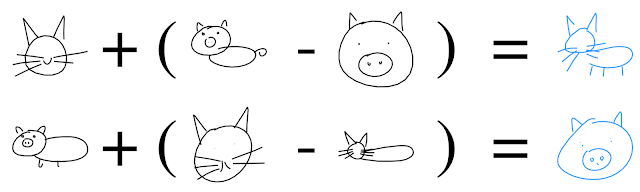
To read more about value of latent spaces in creative applications, see this enlightening paper on Artificial Intelligence Augmentation by some of our colleagues at Google Brain.
How to Learn a Latent Space
There are many different models that are capable of learning latent representations, each having various tradeoffs with regards to the three properties we desire.
One such model is called an autoencoder (AE). An autoencoder builds a latent space of a dataset by learning to compress (encode) each example into a vector of numbers (latent code, or z), and then reproduce (decode) the same example from that vector of numbers. A key component of an AE is the bottleneck introduced by making the vector have fewer dimensions than the data itself, which forces the model to learn a compression scheme. In the process, the autoencoder ideally distills the qualities that are common throughout the dataset. NSynth is an example of an autoencoder that has learned a latent space of timbre in the audio of musical notes:
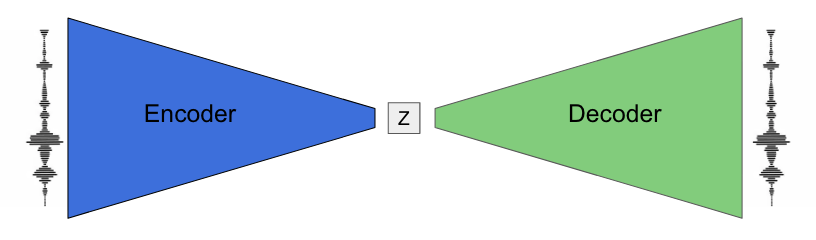
One limitation with this type of autoencoder is that it often has “holes” in its latent space. This means that if you decoded a random vector, it might not result in anything realistic. For example, NSynth is capable of reconstruction and interpolation, but it lacks the realism property, and thus the ability to randomly sample, due to these holes.
Another way to enforce a bottleneck that doesn’t suffer from this problem is by using what is called a variational loss. Instead of limiting the dimensions of the vectors, the encoder is encouraged to produce latent codes with a predefined structure, for example that of samples from a multivariate normal distribution. Then, by constructing new codes with this structure, we can ensure that the decoder produces something realistic.
SketchRNN is an example of a variational autoencoder (VAE) that has learned a latent space of sketches represented as sequences of pen strokes. These strokes are encoded by a bidirectional recurrent neural network (RNN) and decoded autoregressively by a separate RNN. As we saw above, this latent space has all of the properties we desire, thanks in part to the variational loss.
Latent Spaces of Loops
With MusicVAE, we began with a very similar architecture as SketchRNN to learn a latent space for melodic fragments (loops) that includes all of the desired properties. We demonstrate our results here with a few examples.
First, we will demonstrate our ability to morph between two sequences, blending properties of them as we do. While we showed an example of blending two melodies at the very beginning of the post, let’s do something a bit harder and morph from a bassline to a melody:
We will first attempt to smoothly morph from the bassline to the melody without using MusicVAE, simply by sampling notes between the two, akin to cross-fading in audio. Below you can see and hear the result of this naive interpolation. The first segment (black) is the bassline and the final segment (black) is the melody. The red segment is the first step of the interpolation, and the purple is the final one. Each segment is 4 seconds (2 bars).

While the start (red) and end (purple) segments perfectly match the original sequences (black), the intermediate ones are unrealistic both as melodies and basslines. Nearby scores do have similar notes, but the higher-level qualities are lost. The output space has expression but lacks realism and smoothness.
On the other hand, below is a morph performed by interpolating through MusicVAE’s latent space:

Notice that the intermediate sequences are now valid, and the transitions between them are smooth. The intermediate sequences are also not restricted to selecting from the notes in the originals as before, and yet the note selection makes more musical sense in the context of the endpoints. In this example we fully satisfy properties of expression, realism and smoothness.
We also trained this architecture on drum loops, achieving similar results:
Long-Term Structure
One of the places language models (such as MelodyRNN and PerformanceRNN) fall short is that the outputs they generate generally lack coherent long-term structure. As we showed previously with SketchRNN, a latent space model can encode long-term structure to produce full sketches.
However, to achieve a similar result in long musical sequences, which typically have many more steps than the sketches, we found we could not rely on the same architecture. Instead, we developed a novel hierarchical decoder that was capable of generating long-term structure from individual latent codes.
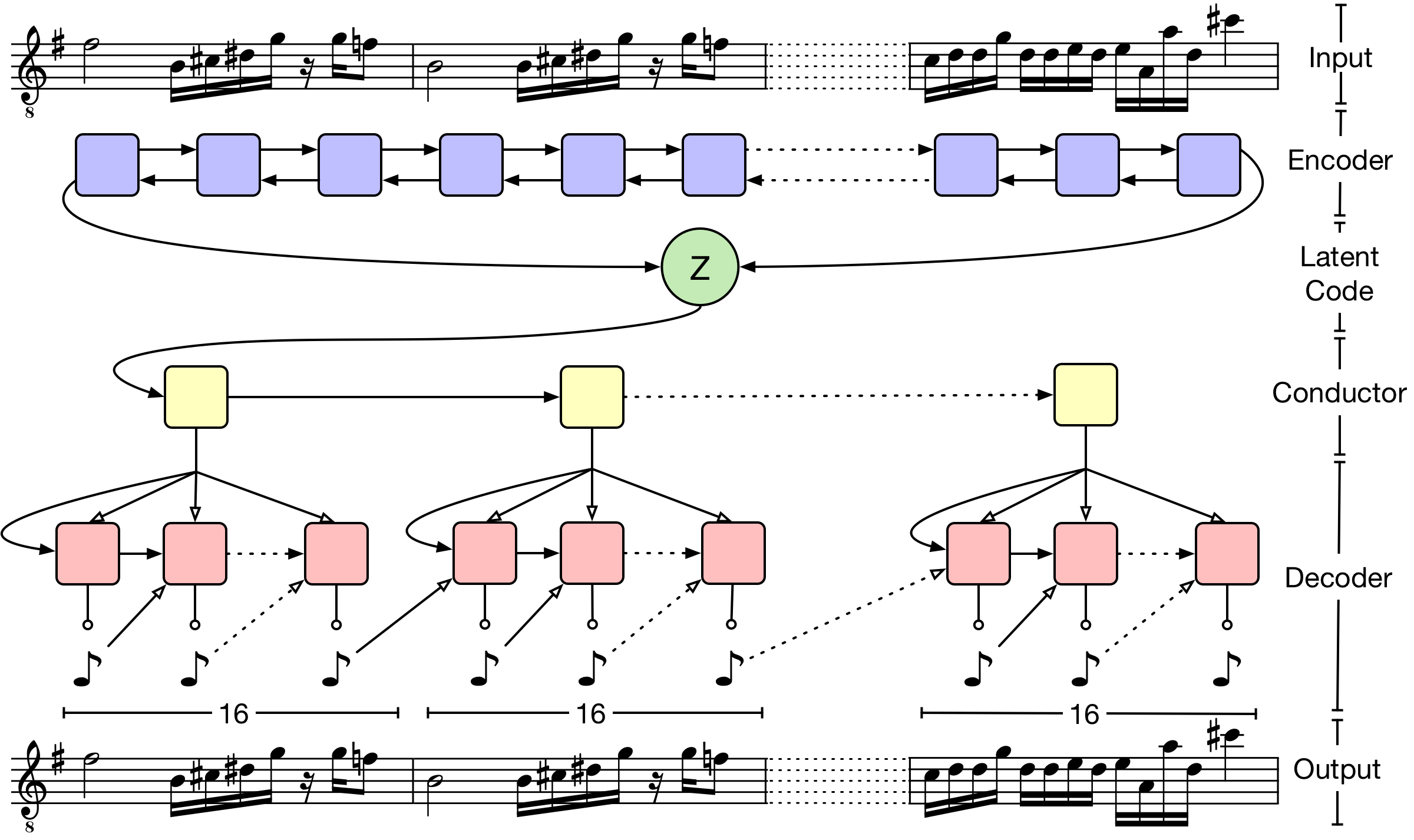
Rather than using our latent code to initialize the note RNN decoder directly, we first pass the code to a “conductor” RNN that outputs a new embedding for each bar of the output. The note RNN then generates each of the 16 bars independently, conditioned on the embeddings instead of the latent code itself. We then sample autoregressively from the note decoder.
We found this conditional independence to be an important feature of our architecture. Since the model could not simply fall back on autoregression in the note decoder to optimize the loss during training, it gained a stronger reliance on the latent code to reconstruct the sequences.
Using this architecture, we are capable of reconstruction, sampling, and smooth interpolation as before, but now for much longer (16-bar) melodies. Here we blend between example melodies A (top) and B (bottom):
| Melody A | 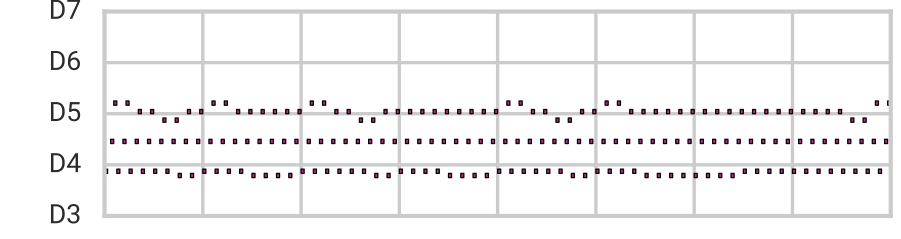 |
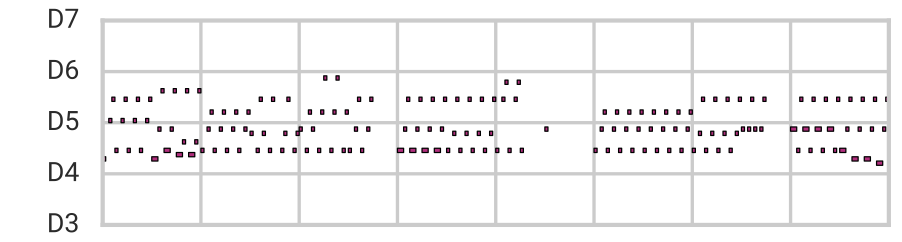 |
|
| Mean | 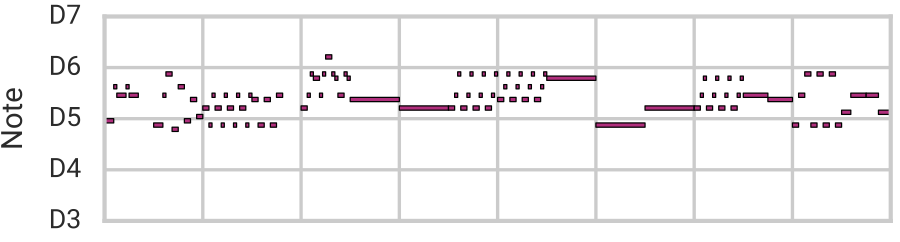 |
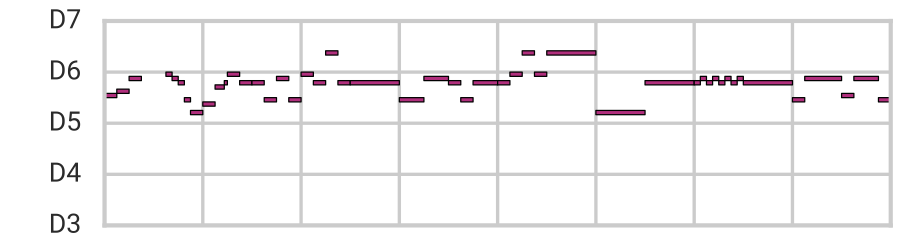 |
|
| Melody B | 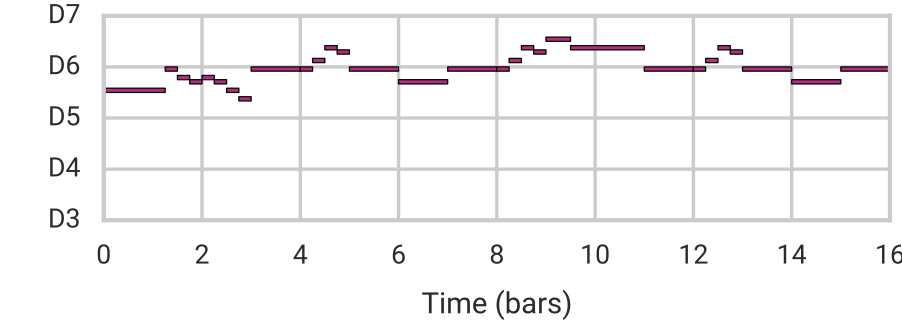 |
You can compare this to a baseline interpolation in data space in the paper’s online supplement.
Furthermore, we can use attribute vector arithmetic (recall the “cat face vector” above) to control specific qualities of the music, while preserving many of its original characteristics including the overall structure. Here we demonstrate our ability to adjust the number of notes in a melody by adding/subtracting a “note density vector” to/from the latent code.
| Subtract Note Density Vector | 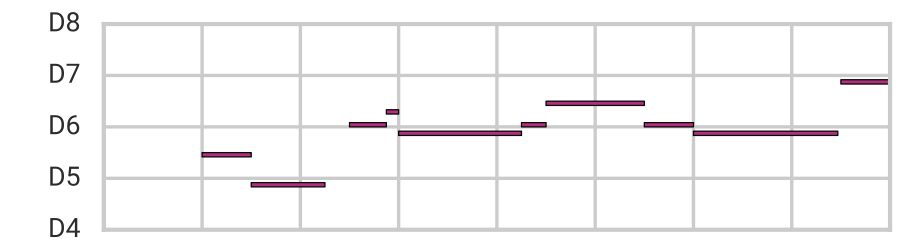 |
| Original | 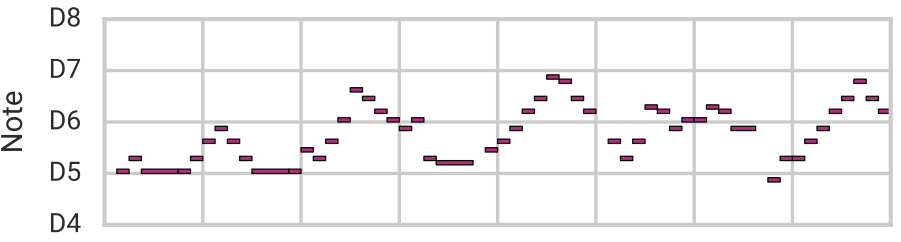 |
| Add Note Density Vector | 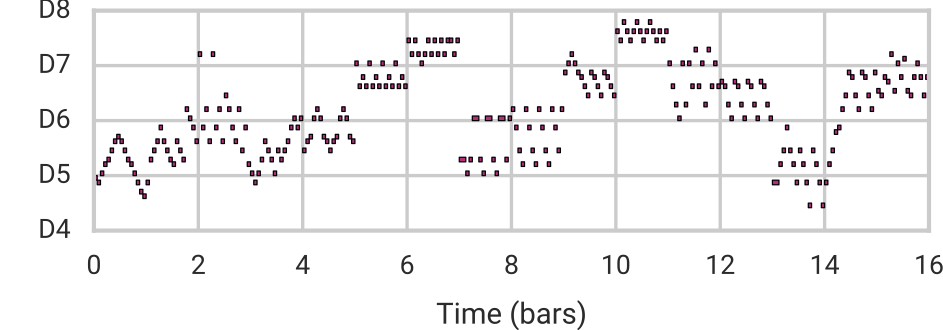 |
Notice that notes are not simply repeated to increase their density. Instead MusicVAE adds arpeggios and other musically-relevant flourishes. Listen to more examples of attribute vectors in the paper’s online supplement.
Getting the Band Back Together
After convincing ourselves (and hopefully you!) that we can model individual instruments with both short and long-term structure, we adapted our hierarchical architecture to model the interplay between different instruments. Instead of passing the embeddings from the conductor to a single note decoder, in these models we pass each embedding to multiple decoders, one for each instrument or track.
By representing short multi-instrument arrangements in the latent space, we can do all of the same manipulations that we did for single melodies. For example, we can interpolate between two 1-measure arrangements for any of 8 completely different instruments. Below is synthesized audo for two interpolations between pairs of random points in latent space, with instrumentation selected by the model. Each point represents 2 seconds (1 bar).
We can also add back the level of hierarchy spanning across bars to model 3 canonical instruments (melody, bass, and drums) over 16-bar sections. This playlist of samples from our “trio” model demonstrate that it has learned how to model the interplay between three instruments over long time frames:
A Tool for Musicians
We’ve just scratched the surface of possible applications of the musical palette learned by MusicVAE for musicians, composers, and music producers, and have already begun to collaborate with developers to make them accessible to as many people as possible.
One example is the Melody Mixer built by creative technologists at Google’s Creative Lab. It allows you to easily generate interpolations between short melody loops. Give it a try and read more on their blog post.

Another is Beat Blender, also by Creative Lab. You can use it to generate two dimensional palettes of drum beats and draw paths through the latent space to create evolving beats. The 4 corners can be edited manually, replaced with presets, or sampled from the latent space to regenerate the palette.
A third is Latent Loops, by Google’s Pie Shop. Latent Loops let’s you sketch melodies on a matrix tuned to different scales, explore a palette of generated melodic loops, and sequence longer compositions using them. Musicians can create full melodic lines using this interface and then easily move them over to their DAW of choice.
What can you do?
We feel that the best people to explore the applications of MusicVAE are like many of you reading this post: creative coders, musicians, composers, and researchers. Therefore, in addition to a TensorFlow implementation of MusicVAE, we are also releasing a MusicVAE JavaScript package built on tensorflow.js along with several pre-trained models. This package allows you to easily develop web apps that can access the full functionality of a pre-trained MusicVAE, in the browser. Have a look at this tutorial to learn how to use it to create your own interface.
We’d love to hear the music you make and try the interfaces you build with MusicVAE! Please share them with the Magenta community on our discussion list.
Additional Resources
- Read the technical details of the model architecture in our arXiv paper.
- Play with MusicVAE’s 2-bar models in your browser with Melody Mixer, Beat Blender, and Latent Loops.
- Learn how to use the JavaScript implementation in your own project with this tutorial.
- Sample and interpolate with all of our models in a Colab Notebook.
- View the Tensorflow and JavaScript implementations in our GitHub repository.
- Hear more examples in the paper’s online supplement and this YouTube playlist.
Acknowledgements
We’d like to thank Douglas Eck, Erich Elsen, David Ha, Claire Kayacik, Signe Nørly, Catherine McCurry, and Shan Carter for their helpful feedback on this blog post. Thanks to Torin Blankensmith and Kyle Phillips from the Creative Lab for their work on Melody Mixer and Beat Blender. Thanks to Catherine McCurry, Zach Schwartz, and Harold Cooper for their work on Latent Loops.
Edited: Labels added to clarify which audio samples are from the VAE.