Editorial Note: We’re excited to see more artists using Magenta tools as a part of their creative process. Here, Sebastian Macchia shares how he used Music Transformer when creating his album, “Nobody’s songs”. If you’re interested in doing similar explorations, our recently relesed Listen to Transformer is a great way to browse starting points.
Nobody’s songs is an album composed with the help of Magenta’s Music Transformer neural network. In this post I will write about the process I went through to make an album with artificial intelligence and all the decisions I took along the journey.
Motivation
The initial idea was to use a generative model from a deep neural network architecture to create music that has good enough harmony and melody and is acceptable as music composed by a human being.
I usually work with organic kind of sound using samplers of acoustic instruments so symbolic representation (MIDI) was a good option to use in a DAW (my choice: Ableton Live). In order to simplify the process the idea was to use single track polyphonic MIDIs.
About the style I thought of the French classical composer Erik Satie, and particularly the compositions that he called “furniture music”, sounds that were designed to be heard but not listened to, what we call nowadays background music.
So I used Onsets and Frames to convert some wavs of Satie’s music to MIDI files. Even though I tried some techniques to do data augmentation, the MIDI dataset was not big enough to train a deep neural network so the results training a basic LSTM network was not good (as I expected).
Using Music Transformer
After several tests with different options (baseline LSTM, performance RNN, MusicVAE) I was surprised by the initial results I obtained using the Music Transformer colab implementation. The expressing timing and dynamics were much better than the other models I tried. Also, the transformer model is able to capture repeating patterns in a way LSTMs cannot so finally I decided to go deep into the notebook and play with the model.
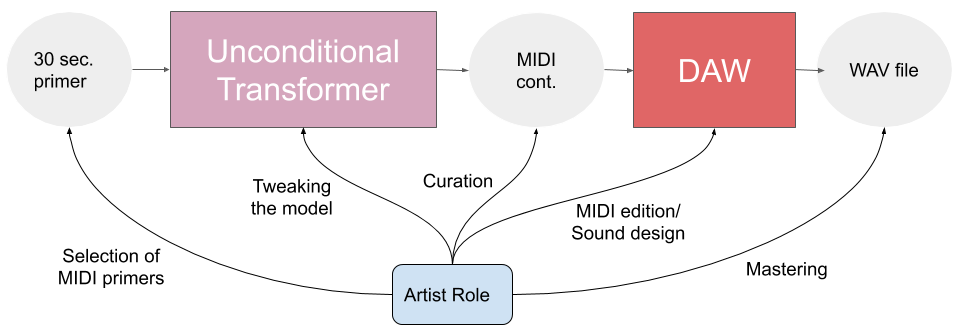
In the colab there are two models: unconditioned and melody-conditioned. The unconditional transformer has two options: getting a sample from scratch and generating a continuation.
I worked with the last option (continuation generator) using the Satie’s MIDIs as primers.
The version of the model in the colab allows no control over how long the generated continuation should be, it releases an end token to decide when to stop so I got sometimes just a 10 sec midi primer generates 2 min continuation but a 40 sec long stop suddenly adding just 10 extra sec.
By doing several tests I was able to prove that a primer with fewer notes generated longer continuations and that approx. 30 sec of MIDI premier was enough to “inspire” the model to generate some decent continuations.
The curator is the new composer
One of the main artist roles in the process of the creation using this kind of model is the selection of the many outputs the model generates. The artist must sift through all of them and select those that are “good enough” to use to generate the final artwork.
I got more than a hundred of midi continuations with different Satie midi primers, some of them not so good:
Many aren’t too bad but didn’t get to the final list.
And others that deeply touched me as soon as I heard them, went straight to the final selection.
Listening with professional musicians
When I finished my first pre-curation I invited two professional musicians to listen to the selection with me and analyze the results musically.

Some of the comments about the results:
“Impressionist colors with romantic touches that at times reminds of Chopin”.
“Simple, light and expressive textures with a free and unpredictable time that conveys calm and tranquility”.
Finally, they helped me to make the selection of the 9 tracks.
Working on the DAW
After curating the outputs and selecting the most potential MIDIs I started working with different options in Ableton Live. I finally ended working with a session with three tracks: The main track with the transformer’s continuation triggering a grand piano, other MIDI track with melody with another piano (a brighter one) and a further track with a double bass.
Here you have every step of the process with the first track, starting with the primer:
With that primer the model generated this continuation:
Then I edited the continuation: changed some velocities, lengthened some notes, corrected the intonation and decreased the tempo. After all these changes this track sounds like this:
Then another track is playing the melody (some notes that are taken from the previous main track).
And one more track for the double bass that harmonizes the chords:
Finally, I added a vinyl crackling sound background that makes an effect of a dust record that increases that feeling of nostalgia or aesthetic Déjà vu that the songs awake in me.
The final track is this one:

This process is basically the same for all the tracks. Although I do some editions over the main track (main tempo, velocity, pitch correction over some notes), the final output keeps the original spirit of the one generated by the model.
Here you have a repository of all the MIDIs which contain the primers alongside the corresponding continuation I finally use in the DAW.
Cover and song names
Other aspects of the album were also made using generative neural network. The album cover was made with Artbreader, which uses a Generative Adversarial Network.
The song titles are new names taken from a Long-Short term Memory network trained with 20.000 female and male names.
Conclusion and future works
Music Transformer is a really good option to generate MIDI compositions that producers can import in the DAWs to help the creation of new tunes.
The model uses the primers motif and creates new phrases that are musically coherent in the long-term.
The colab implementation is a bit limited in its controllability, no control over temperature, style, speed, time, etc. It could be very useful to implement some controls in the future.
Using the colab implementation we use the checkpoints of a pre-trained model. Indeed, one of the main reasons the model generated such quality music is the huge dataset it is trained with (10.000 hours of piano music). Despite the difficulty of training a model with that amount of data, it would be good in the future to train the model with our own datasets.