In this post we’d like to introduce a new dataset and a new music transcription model, this time for drums! Our new model is based on our Onsets and Frames architecture, originally for piano. We’re calling this model OaF Drums. We trained OaF Drums on a new dataset we’re calling the Expanded Groove MIDI Dataset (E-GMD). We are making E-GMD available under a Creative Commons Attribution 4.0 International (CC BY 4.0) License.
 Colab Notebook Colab Notebook |
🎵E-GMD Dataset | 📝arXiv Paper |  GitHub Code GitHub Code |
OaF Drums converts raw recordings of solo drum performances into MIDI with predicted timings, drum hit classification, and velocity.
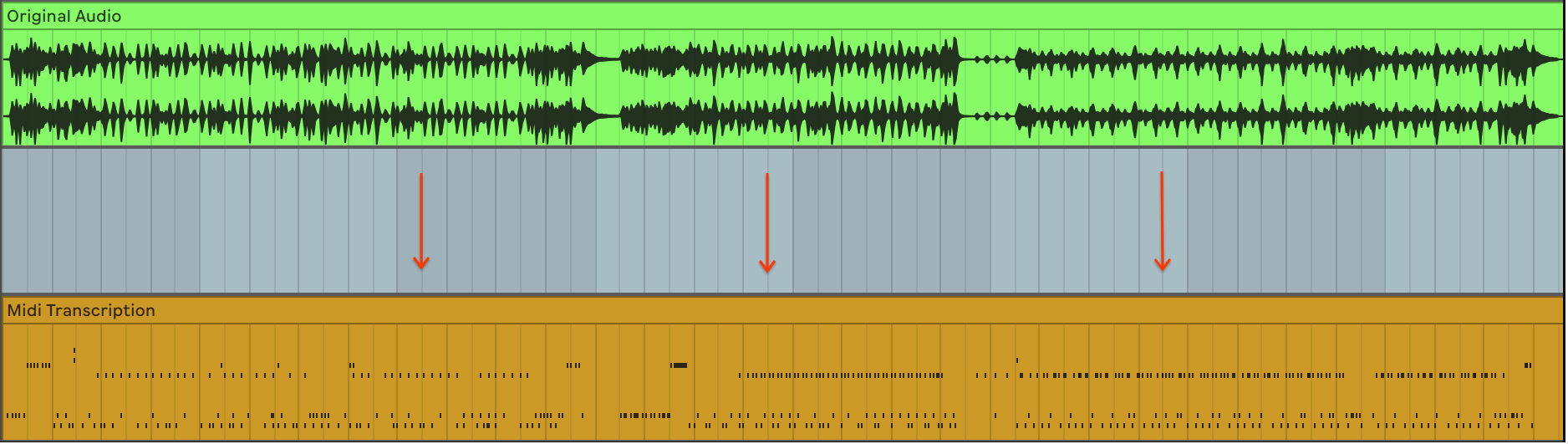
All of these predicted components come together to allow OaF Drums to fully capture the essence of a beat.
As a practicing musician, you can utilize the model to have a better understanding of your own timings and groove, and to assess whether you are consistently maintaining the tempo and swing on any kit you possess. You can use this model to transcribe new beats or polyrhythms that are difficult or tedious to manually transcribe. You can play in beats on an acoustic drum kit and have an accompanying MIDI reperesentation of your performance for further use in music production (such as adding accompanying electronic sounds to your acoustic kit).
Automatic transcription also opens up many new possibilities for analyzing music that isn’t readily available in notated form, to create much larger training datasets for generative models. We’ve done this exact thing in using our Onsets and Frames piano model for the Piano Transformer.
Dataset
The success and capabilites of OaF Drums are not possible without a sufficiently large dataset to train against, and we created E-GMD with that goal in mind. E-GMD is a large collection of human drum performances, with audio recordings annotated in MIDI. It is also the first human-performed drum transcription dataset with annotations of velocity. E-GMD contains 444 hours of audio from 43 drum kits recorded on a Roland TD-17 and is an order of magnitude larger than similar datasets. It is based on our previously released Groove MIDI Dataset. We are making E-GMD available because we believe it has several advantages over existing datasets. E-GMD’s breadth of drum kits, human (vs. scored) performances, velocity annotations, and overall size give it a huge value to research.
| Dataset | Duration (Minutes) | Velocity Annotation |
| E-GMD | 26,670 | Yes |
| ENST | 61 | No |
| MDB Drums | 21 | No |
One of the main intentions in recording E-GMD was to record a large collection of drum kits and timbres. This allows OaF Drums to transcribe beats from a diversity of drum sounds. Take a listen to the following examples to get a clearer picture of the different types of drum kits that we recorded in our dataset.
Perceptual Quality and performance
Given OaF Drums capabilities for predicting velocity alongside drum hit and timing, the model achieves state of the art drum transcription when measuring for perceptual quality. In a pairwise listening study conducted against other top performing drum transcription models, OaF Drums had the best performance.
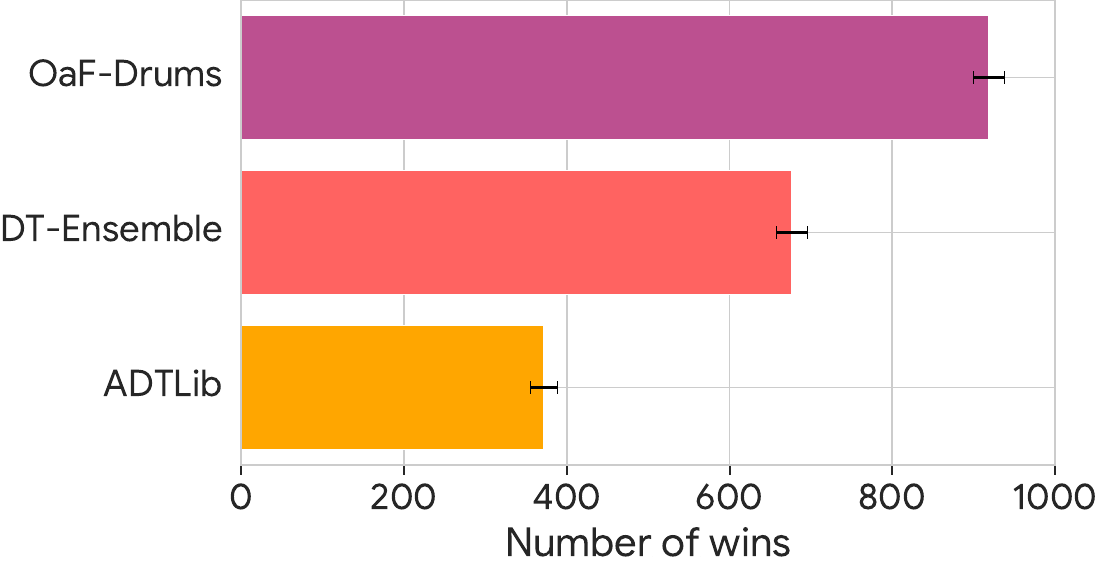
Also as a part of the listening study, we were able to assert that velocity transcription is a very important contributor to perceptual quality. We duplicated the transcriptions of OaF Drums and applied a constant fixed velocity value, to emulate the behaviors of the other drum transcription models that do not predict velocity at all. With fixed velocity, OaF Drums had less favorable performance against the other models. This provides a lot of evidence to how important velocity is in capturing groove. More details on the listening study can be found in our accompanying paper on arXiv: Improving Perceptual Quality of Drum Transcription with the Expanded Groove MIDI Dataset.
| Model | Number of Wins |
| OaF Drums | 919 |
| OaF Drums (Fixed Velocity) | 456 |
The differences between fixed velocity and predicted velocity are audible in comparison. Below are a set of examples from our E-GMD test set that have both fixed velocity and predicted velocity transcriptions.
| Input Audio | |
| Transcription (Fixed Velocity) | |
| Transcription |
| Input Audio | |
| Transcription (Fixed Velocity) | |
| Transcription |
We find that velocity prediction can go a long way in making transcription models valuable for downstream applications, such as generative music models like the Music Transformer. Imagine the difference between a generative model such as Music Transformer, that is trained on examples coming from a fixed velocity transcription model versus a predicted velocity prediction model. Fixed velocity models lose a lot of the performance and evocative aspects of music, and that impact would dramatically lessen a generative model’s ability to provide interesting musical ideas to a musician.
Conclusion
Overall, OaF Drums is capable of transcribing a large spectrum of drum kits and and drum sounds. In spite of training on synthetic sounds and samples derived from a Roland TD-17, the model still shows a strong capacity to transcribe acoustic drums (as seen in the video above) alongside electronic kits, like the 808. However, the model is still not without its limitations. For example, the model has a tendency to under predict crashes. This is likely because of the diversity of crash timbres that are possible, depending on the size and shape of a crash and how it is hit. Additionally, there are not as many datapoints of crashes in our dataset compared to, say, kicks and snares, which are far more fundamental to typical drum beats. In early training, our model is naturally incentivized to be conservative in predicting crashes because of how infrequently they occur. Thus they have less impact in the loss. It is certainly an opportunity for future work!
We’d love to hear your experience with the drums model. Try out the drums model by visiting the Onsets and Frames Colab Notebook or using the code on GitHub. Please let us know how the model has worked for you on the magenta-discuss group. We’d love to have you share any interesting (good or bad) transcription results you find!
How to Cite
If you use the E-GMD dataset or OaF Drums in your work, please cite the paper where it was introduced:
Lee Callender, Curtis Hawthorne, and Jesse Engel. "Improving Perceptual Quality
of Drum Transcription with the Expanded Groove MIDI Dataset." 2020.
arXiv:2004.00188.
You can also use the following BibTeX entry:
@misc{callender2020improving,
title={Improving Perceptual Quality of Drum Transcription with the Expanded Groove MIDI Dataset},
author={Lee Callender and Curtis Hawthorne and Jesse Engel},
year={2020},
eprint={2004.00188},
archivePrefix={arXiv},
primaryClass={cs.SD}
}