The goal of the Magenta project is not just to build powerful generative models, but to use those models to empower people to realize their creative goals. In seeking to optimize our models for human values, instead of just imitating datasets, we collaborate closely with Human-Computer Interaction (HCI) researchers (such as our great collaborators in People + AI Research (PAIR)) to iterate on our models, develop new interfaces for control, and find new ways to evaluate the true impact of our work.

We’re excited about the potential of such tight-knit collaboration between machine learning (ML) and HCI researchers to create better models and interfaces that empower people using machine learning for creativity. This post highlights a collection of this work that investigates how to promote creative ownership when co-creating with AI, express and communicate emotion through AI generated music, and use AI to mediate human-to-human collaboration.
| 🎵Create Music with COCOCO | 📝COCOCO Paper | 📝Expressive Communication Paper | 📝Human-Human Collaboration Paper |
Promoting Ownership in Human-AI Co-Creation
Recent generative music models have made it possible for anyone, regardless of their musical experience, to compose a song in partnership with AI. For example, the “Bach Doodle” was Google’s first-ever ML powered Doodle. By providing only a few notes, users could co-create a four-part composition with the AI in the style of J.S. Bach. This enabled anyone on the web to make new music in their browser. After the release of the Bach Doodle, we became curious how novice composers engage in co-creation activities like these, and how the design of the interactive tools could impact whether they feel personally-empowered when making music with generative models. In a user study with novice composers, we found that users can struggle to evaluate or edit the music when ML models generate too much content at once. Others wanted to go beyond randomly “rolling dice” to generate a desired sound, and sought ways to control the generation based on relevant musical objectives.
To improve the co-creation partnership, we developed COCOCO, a music editor web-interface that includes a set of AI Steering Tools that allowed users to restrict generated notes to particular voices and “nudge” outputs in semantically-meaningful directions. For example, a user could choose to generate a single accompaniment in the bass voice, and steer the generation to sound more sad.
In a comparison study, we found that these new tools helped users increase their control, creative ownership, and sense of collaboration with the generative ML model. By observing and asking questions about novices’ strategies when composing, we found that the tools allowed people to compose the song bit-by-bit, and promoted controlling and understanding each part of the piece more than if the AI generated it all at once. This study showed that providing interfaces to partition and constrain the generation of an existing ML model can make a significant difference in composers’ creative experience and their partnership with the AI.
We invite you to make music using COCOCO!
If you’d like to use or extend this work, please cite our full paper published at CHI’20.
@inproceedings{louie2020novice,
title={Novice-AI music co-creation via AI-steering tools for deep generative models},
author={Louie, Ryan and Coenen, Andy and Huang, Cheng Zhi and Terry, Michael and Cai, Carrie J},
booktitle={Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems},
year={2020},
url = {https://doi.org/10.1145/3313831.3376739}
}
Expressing and Communicating Emotion in Co-created Music
ML models are becoming more expressive and capable of generating music with long-range coherence. At the same time, better HCI interfaces for controlling them can promote feelings of ownership, as we saw with our previous project on COCOCO. While these parallel efforts are aimed at empowering the end-user, less is known about how ML models and HCI interfaces can impact a creator’s subjective experience, and how people objectively perform on a creative task, such as composing music to express an emotion.
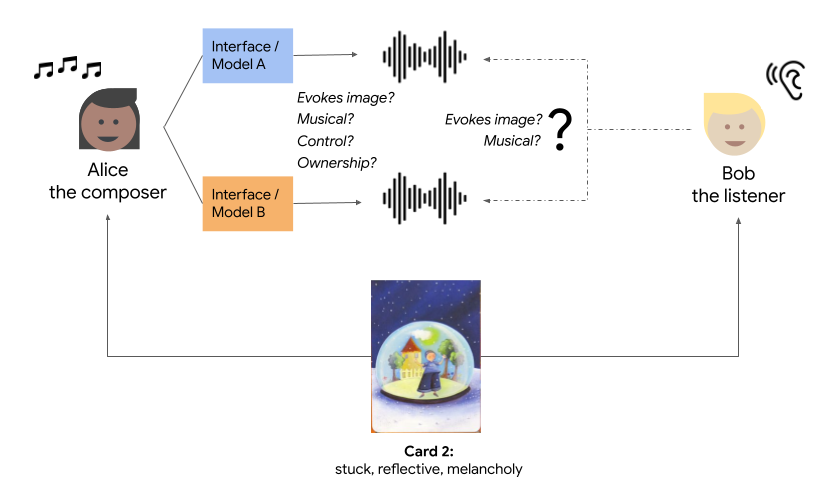
We created a unified framework called Expressive Communication to jointly evaluate the impact of ML and HCI advances in empowering expression. For the creative task, composers use different versions of a generative AI tool to create music with the goal of communicating a particular image and human emotion. This was inspired by real-world music creation tasks, such as making background music for a video, or creating music to set the mood for a scene in a film or video game. Additionally, the framework provides an objective measurement by using an outside listener to judge how the created music better evokes the intended imagery and emotions. We used this framework to compare two generative models capable of different degrees of long-range structure and musical coherence, and two different interfaces capable of different degrees of steering and iterative composition.
Our results show that both the ML and HCI approaches (developing better pretrained models and better steering interfaces, respectively) are important and complementary ways to support composers in both communicating through music and feeling empowered in the process of co-creating with generative models. Our results also shed light on how objectives of a pretrained model, such as stronger coherence, can make certain emotions such as “fear” more difficult to express with curation of random samples alone, and how the addition of steering interfaces can help to mitigate model biases by creating samples that are less likely from the model, but more aligned with the user’s expression and musical goals.
If you’d like to use or extend this work, please cite our recent paper.
@misc{louie2021expressive,
title={Expressive Communication: A Common Framework for Evaluating Developments in Generative Models and Steering Interfaces},
author={Louie, Ryan and Engel, Jesse and Huang, Anna},
year={2021},
eprint={2111.14951},
archivePrefix={arXiv},
primaryClass={cs.HC}
url={https://arxiv.org/abs/2111.14951}
}
Listen to the music and guess which generative tool was used
We created an interactive game for you to engage more as a reader and listener! We ask you to listen to two pieces of music created for the same emotion, and then guess which generative tool was used to make the compositions below.
Remember that more expressive models and more steerable interfaces led to more emotionally evocative and musically coherent pieces. Use this insight when guessing!
Which music was made with the more vs. less expressive model?

Which music was made with the more vs. less steerable interface?

Mediating Human-Human Collaboration with AI
Although there’s been a lot of recent research on human-AI collaboration, less is known about how generative ML tools, like the ones we are developing at Magenta, could affect human-human collaboration. Our HCI collaborators at Google studied the social dynamics of pairs of people composing music together, with and without the help of a generative music model.
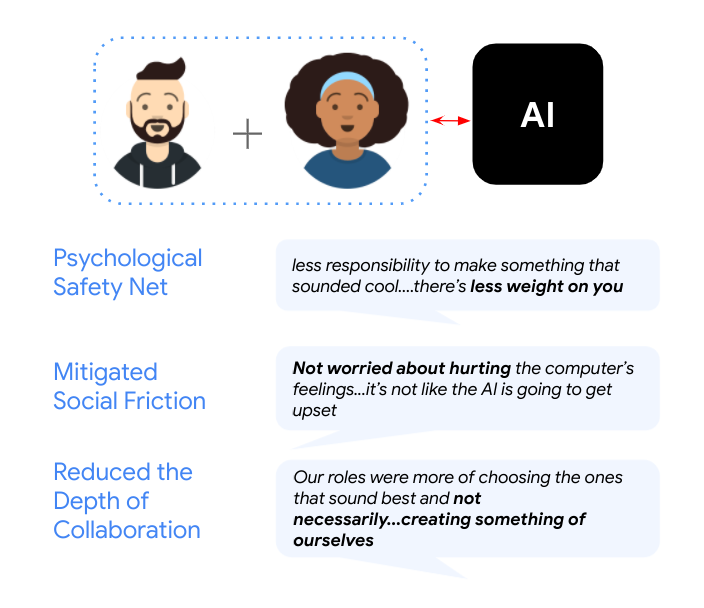
We found that generative AI models can act as a “social glue” in co-creative activities — for example, generative AI helped human collaborators maintain forward momentum and cordiality in moments when there were creative tensions or disagreements. It also helped initially establish common ground between strangers, and served as a psychological safety net. Despite increasing the ease of collaboration, however, AI assistance may reduce the depth of human-human collaboration. Rather than grappling with each other’s ideas, users often offloaded that creative work to the generative AI. Users sometimes indicated that they felt more like joint “curators” or “producers” of art, rather than as the “composers” themselves. Researchers, designers, and practitioners should carefully consider these tradeoffs between ease of collaboration and depth of collaboration when building AI-powered systems.
If you’d like to use or reference this work, please cite our paper published at CHI’21.
@inproceedings{suh2021ai,
title={AI as Social Glue: Uncovering the Roles of Deep Generative AI during Social Music Composition},
author={Suh, Minhyang and Youngblom, Emily and Terry, Michael and Cai, Carrie J},
booktitle={Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
year={2021},
url = {https://doi.org/10.1145/3411764.3445219}
}
Conclusion
These projects on promoting ownership, supporting emotional communication, and exploring human-human music creation are just a taste of what is possible when people are put first during the entire lifecycle of developing and studying generative models. This is the reason to engage in these types of collaborations now, because the human needs and understanding of the impact on people-centered outcomes are equally important for the development of generative models.
We look forward to working in tandem with researchers to use cutting-edge HCI and ML research to create amazing experiences to delight and empower users. The initial interactive tools and experiences have been developed towards overcoming general challenges that any class of user, like a novice composer, could face. In the future, we hope that HCI + ML collaboration can lead to adaptive interfaces and models which best learn-from and support the personalized behaviors and needs of specific users.
Acknowledgements
Thank you to our paper co-authors for their significant contributions to the works we’ve covered here, including Andy Coenen, Minhyang Suh, and Emily Youngblom. A warm shout out to all the Googlers we have met during user studies: your curiosity and enthusiasm for music and using generative AI tools was energizing and much appreciated, and your thoughts and feedback has greatly impacted this work. Many thanks to the people across Google Research who have offered their help and guidance! Larger Magenta collaborators: Halley Young, Ethan Manilow, Josh Gardner, Sehmon Burnham, Ian Simon, Fjord Hawthorne, Pablo Samuel Castro, Riley Wong. PAIR Collaborators: Martin Wattenberg, Fernanda Viégas, Qian Yang, Sherry Yang, Emily Reif, Ellen Jiang, Alex Bäuerle; Fellow Research Interns: Sherry Tongshuang Wu, Katy Gero, Jialin Song, Guangzhi Sun. And many more!