We present our work on music generation with Perceiver AR, an autoregressive architecture that is able to generate high-quality samples as long as 65k tokens—the equivalent of minutes of music, or entire pieces!
| 🎵Music Samples | 📝ICML Paper |  GitHub Code GitHub Code |
 DeepMind Blog DeepMind Blog |
The playlist above contains samples generated by a Perceiver AR model trained on 10,000 hours of symbolic piano music (and synthesized with Fluidsynth).
Introduction
Transformer-based architectures have been recently used to generate outputs from various modalities—text, images, music—in an autoregressive fashion. However, their compute requirements scale poorly with the input size, which makes modeling very long sequences computationally infeasible. This severely limits models’ abilities in settings where long-range context is useful for capturing domain-specific properties. Music domains offer a perfect testbed, since they often exhibit long-term dependencies, repeating sequences and overall coherence over entire minutes—all necessary ingredients for producing realistic samples that are pleasing to the human ear!
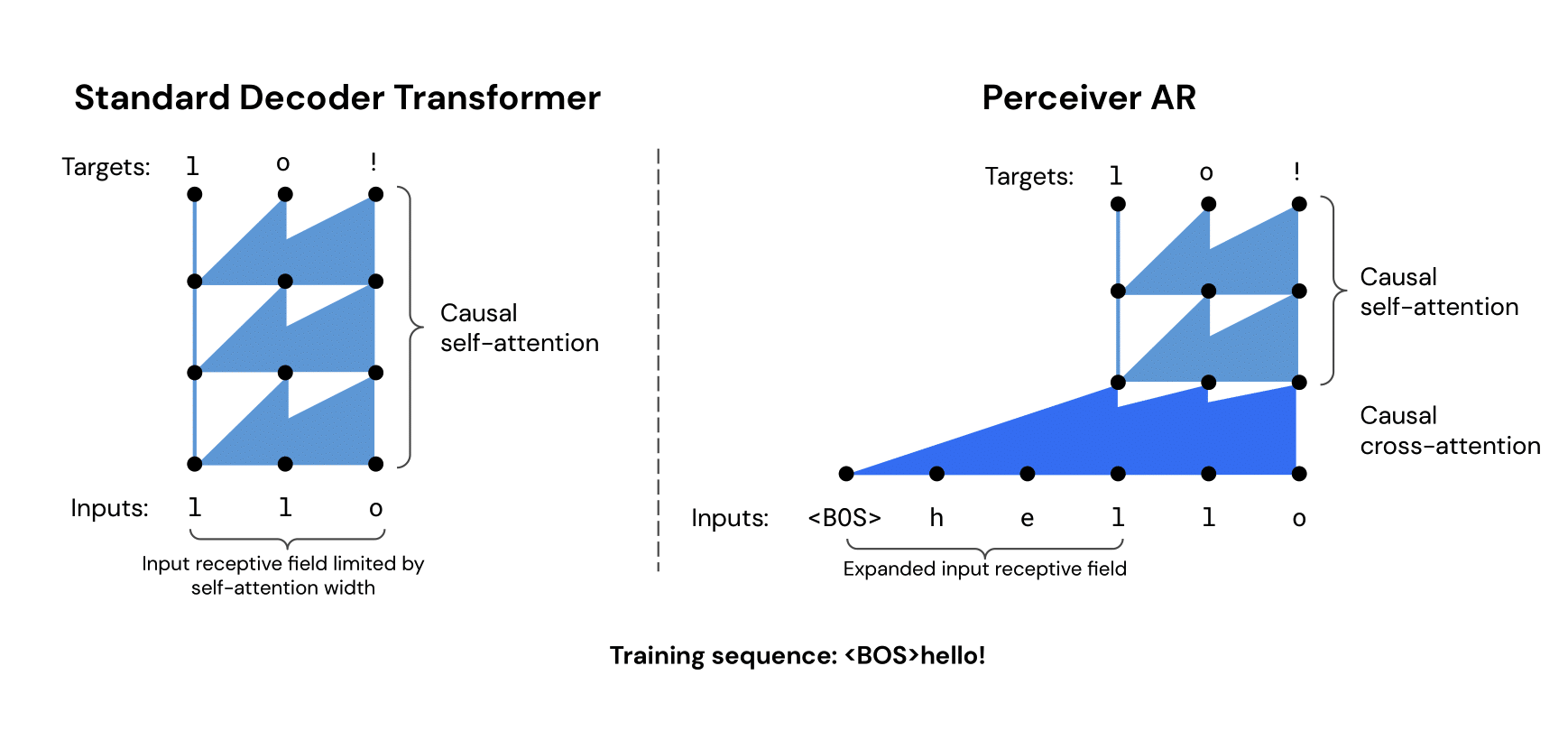
To ameliorate these issues, we propose Perceiver AR, an autoregressive version of the original Perceiver architecture. A Perceiver model maps the input to a fixed-size latent space, where all further processing takes place. This enables scaling up to inputs of over 100k tokens! Perceiver AR builds on the initial Perceiver architecture by adding causal masking. This allows us to autoregressively generate music samples of high quality and end-to-end consistency, additionally achieving state-of-the-art performance on the MAESTRO dataset.
Setup
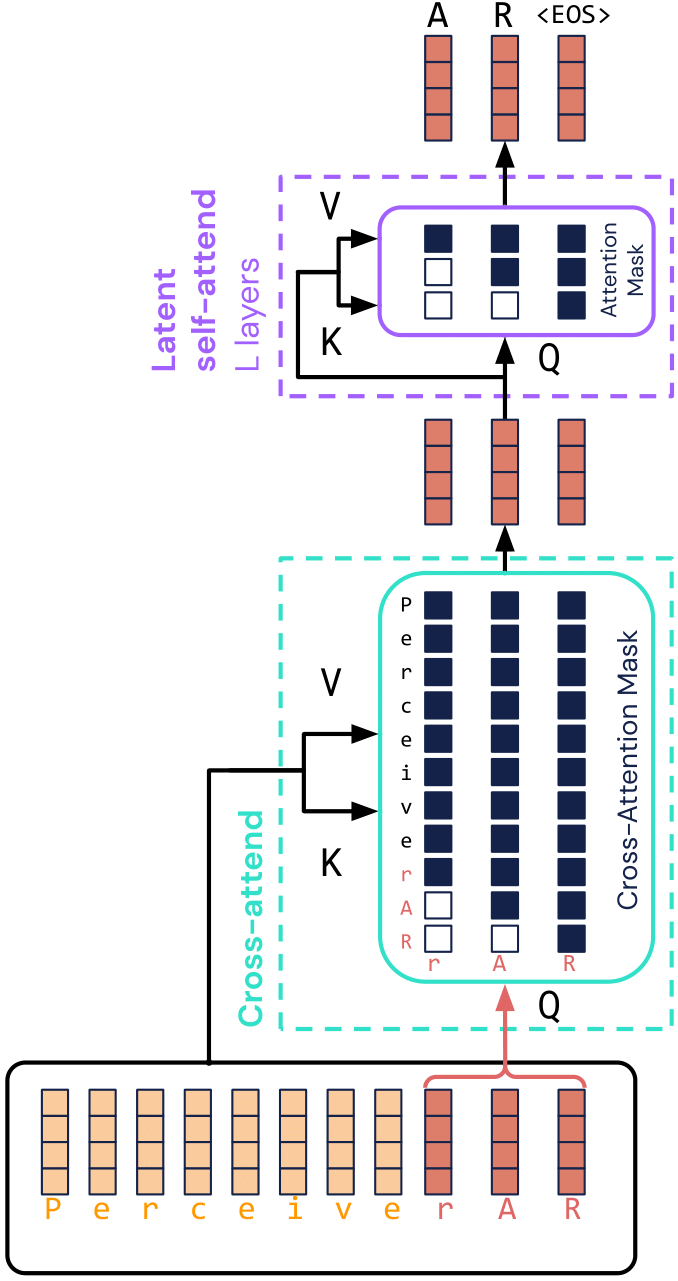
Perceiver AR first maps the inputs (in the diagram, [P,e,r,c,e,i,v,e,r,A,R]) to a fixed-size latent array, via a single cross-attention operation. These latents (3 illustrated above) then interact in a deep stack of self-attention layers to produce estimates for each target. The most recent inputs ([r,A,R]) correspond to queries, and each latent corresponds to a different target position ({1: A, 2: R, 3: <EOS>}).
Causal masking is used in both kinds of attention operations, to maintain end-to-end autoregressive ordering. Each latent can therefore only attend to (a) itself and (b) latents corresponding to ‘earlier’ information (either input tokens or target positions). This respects the standard autoregressive formulation, where the probability distribution for the t-th output is only conditioned on what was generated at previous timesteps 1, ..., t-1.
In the music domain, we use up to 65k-token inputs, which corresponds to several minutes in the symbolic domain and one minute in the raw audio domain.
Symbolic music
The playlist at the top showcases 8 unconditional samples. These were generated by a model that was trained on 10,000 hours of transcribed YouTube piano performances containing examples between 1k and 32k tokens in length. The model had 1024 latents and 24 self-attention layers. Training on this large-scale dataset yields high-quality samples with stylistic and structural coherence—one can identify repeating musical themes, different chord progressions, arpeggios and even ritardandos. Moreover, the main difference from our previous model trained on YouTube piano performances is that a 32k input size was feasible this time, so we only used full-length pieces for training! This allowed Perceiver AR to better model entire pieces with beginning, middle and end sections.
Next, we present audio samples from the symbolic domain, obtained by training on MAESTRO v3. The input representation in both cases was computed from MIDI files as described by Huang et al. in Section A.2, and the final outputs were synthesized using Fluidsynth.
Raw audio
Perceiver AR can also be used to generate samples from the raw audio domain.
Here, we applied the SoundStream codec to
MAESTRO v3 .wav files
to encode the raw audio. After training the model, we generated samples and
decoded them into the source domain. Keeping the context length fixed, we
experimented with 3 different codec bitrates—12kbps, 18kbps, 22kbps—which,
for an input length of 65k tokens, span 54.4s, 36.8s and 29.6s of music,
respectively. The examples below illustrate the trade-off between sample
duration and fidelity: codecs with lower bitrates model coarser structure and
enable training on a longer period of time, but sacrifice audio quality.
| 12kbps | 18kbps | 22kbps |
You can listen to more raw audio samples here 🎵.
Bonus
To end on a high note (🙃), we invite you to enjoy Charlie Chen’s creation - a music box that plays Perceiver AR outputs, adding an immensely nostalgic feel to the generated music!
@inproceedings{
hawthorne2022general,
title={General-purpose, long-context autoregressive modeling with Perceiver AR},
author={Hawthorne, Curtis and Jaegle, Andrew and Cangea, C{\u{a}}t{\u{a}}lina and Borgeaud, Sebastian and Nash, Charlie and Malinowski, Mateusz and Dieleman, Sander and Vinyals, Oriol and Botvinick, Matthew and Simon, Ian and others},
booktitle={The Thirty-ninth International Conference on Machine Learning},
year={2022},
url={https://arxiv.org/abs/2202.07765}
}