Automatic Music Transcription (AMT) is the task of extracting symbolic representations of music from raw audio. AMT is valuable in that it not only helps with understanding, but also enables new forms of creation via training powerful language models (such as Music Transformer) and building interactive applications (such as Piano Genie and Magenta Studio) that rely on symbolic representations of music.
Notes are a powerful and intuitive such representation, motivating our effort to dramatically improve AMT in the past several years. We focused initially on piano transcription with the Onsets and Frames model by Hawthorne et al. and the MAESTRO piano dataset. In 2020, we expanded the set of instruments we’re able to transcribe by adapting Onsets and Frames to drum transcription. However, adding new instruments one at a time is tedious; furthermore these architectures are specifically designed for percussive instruments with well-defined note onsets and less suitable for other instruments.
Recently, we’ve been exploring how to make general-purpose music transcription systems — systems that don’t need to be redesigned by hand for each new instrument or task. In this blog post, we highlight some of our recent advances toward more general music transcription systems.
In short, the main things we’ve discovered recently are:
- Off-the-shelf Transformers work at least as well as custom neural network architectures for piano transcription; we just train the model to take spectrograms as input and output a sequence of MIDI-like note events.
- For multi-instrument transcription, training a single model on basically all existing datasets is very helpful, especially for the smallest datasets.
We discuss each of these below.
Transformers for Piano Transcription
Most work in music transcription over the years has focused on transcribing piano recordings. As we mentioned above, many researchers have hand-designed neural network architectures based on the specifics of how piano notes sound. A great example of this is the Onsets and Frames architecture, which has dedicated output “heads” for the piano note onset, the velocity of the note (how hard it is struck), and the continued presence of the note (i.e. “frames”). Some research goes even further, modeling piano pedal events or the ADSR curves of piano notes.
However, as piano transcription architectures became more task-specific, researchers in other areas of machine learning were using generalized architectures to solve multiple tasks; in particular, the Transformer architecture has shown remarkable performance on a diverse set of tasks within both language and vision. We wondered: is it possible to use Transformers for piano transcription?
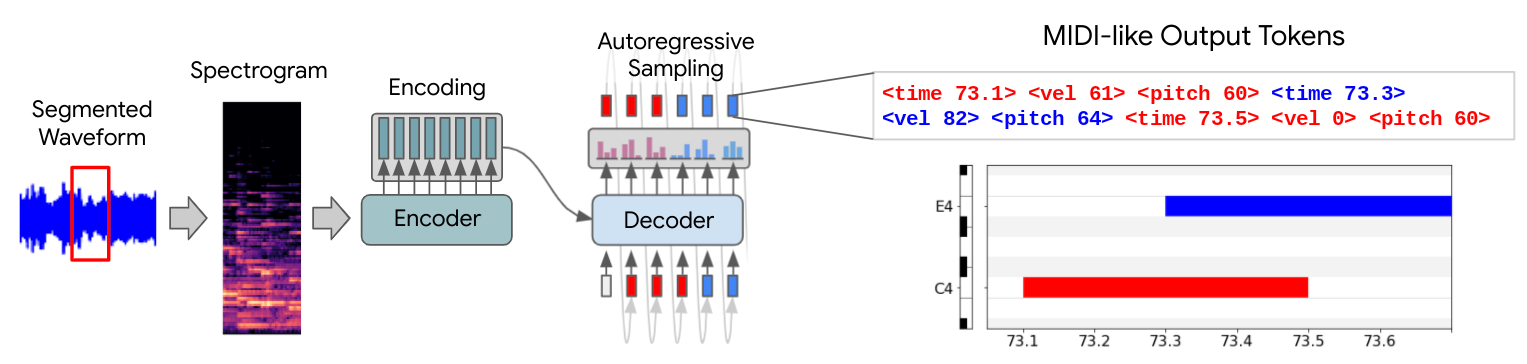
To answer this question, we modeled piano transcription as a sequence-to-sequence task, using the Transformer architecture from T5 (“T5-small” to be specific). We used spectrogram frames as our input sequence, and output a sequence of tokens from a MIDI-like vocabulary to represent note onsets, velocities, and offsets. Despite the simplicity of our approach, we achieved similar or better piano transcription performance (as measured by the F1 metric over notes accounting for onset time, offset time, and velocity) than the previous state-of-the-art hand-designed piano transcription systems:
| Model | F1 |
| Transformer (ours) | 82.18 |
| Kong et al. 2020 | 80.92 |
| Kim & Bello 2019 | 80.20 |
| Hawthorne et al. 2019 | 77.54 |
We found a few tricks very helpful in making Transformer models work for piano transcription:
- Independently-transcribed segments: Because Transformers use memory quadratic in the sequence length, we chop up long input signals into non-overlapping segments of length ~4 seconds, concatenating the outputs to get transcriptions for entire recordings.
- Absolute time events: In our music generation models such as Music Transformer, we use a symbolic language with relative time shifts e.g. "hit C6, move forward 400 ms, release C6". However, for transcription we want our output events to happen at the right time in an absolute sense. We therefore use absolute times in our symbolic output language, to avoid accumulation of small errors over time.
A key advantage of this system is that to train on a new type of transcription task (e.g. only piano note onsets), we only have to change the output vocabulary of the system; with previous systems, one would need to reconfigure the network architecture itself to support new tasks. While training a new system to only output piano note onsets might have limited utility, training a new system to transcribe multiple instruments simultaneously can greatly expand the usefulness of music transcription systems.
Transcribing Multiple Instruments
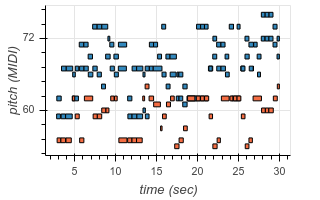
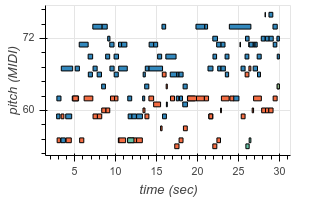
To enable transcription of multiple instruments, we add new tokens to our output vocabulary corresponding to instrument identity. Now, using the same architecture as before, we can transcribe recordings containing multiple different instruments. The following are examples from existing test datasets, transcribed by our model:
| Original | Transcribed |
 |
 |
 |
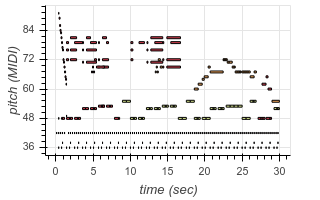 |
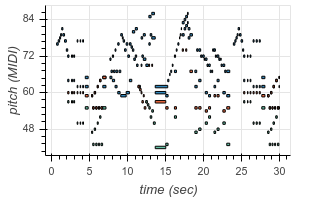 |
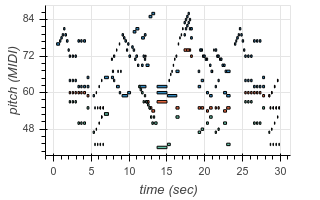 |
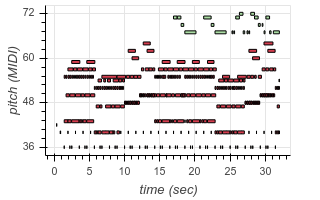 |
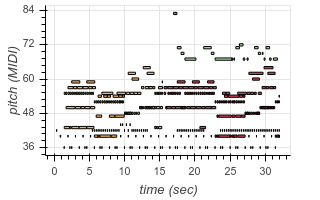 |
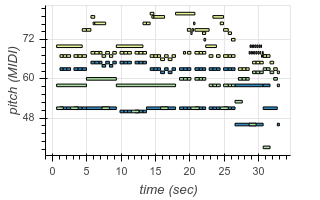 |
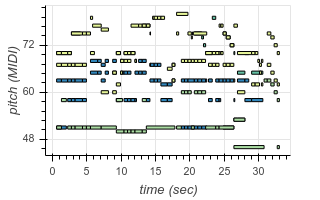 |
These transcriptions are from a single model we call “MT3” (short for Multi-Task Multitrack Music Transcription) which, due to our general setup, we are able to train in multi-task fashion, combining many previously-separate music transcription datasets into a single “mixture”:
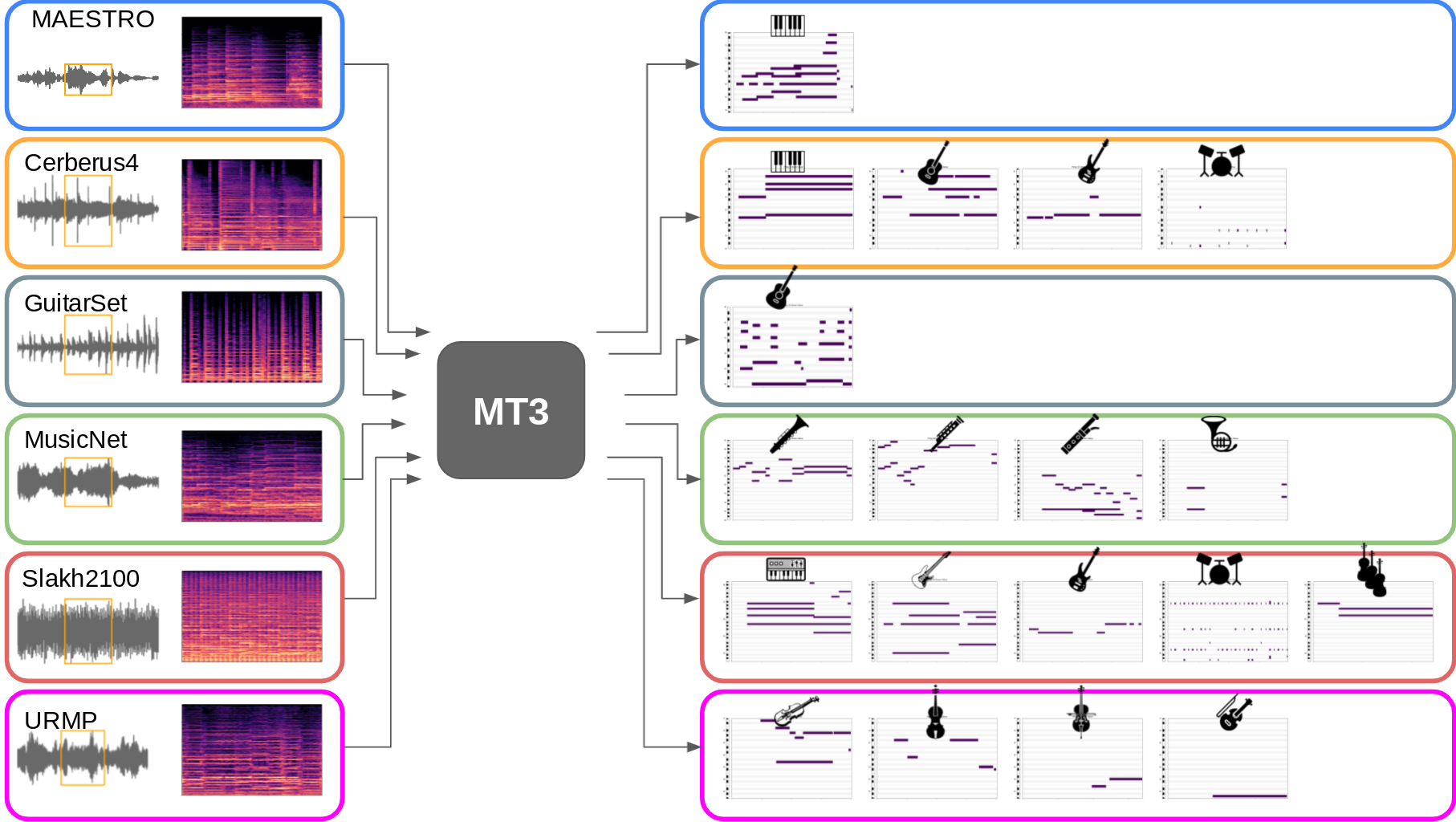
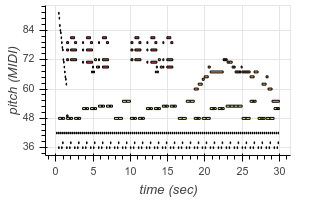
This not only allows us to learn to transcribe several different styles of music with a single model, but also allows our model to leverage large transcription datasets to improve its performance on smaller transcription datasets. The model even demonstrates the ability to perform “zero-shot” transcription in some contexts, transcribing music from datasets it did not see (hear?) during training. For example, here are some transcriptions of audio from YouTube videos:
| Original | Transcribed |
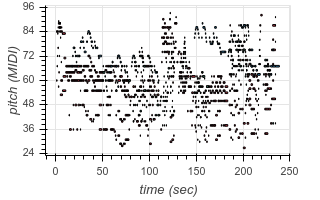 |
|
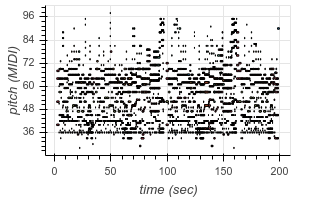 |
|
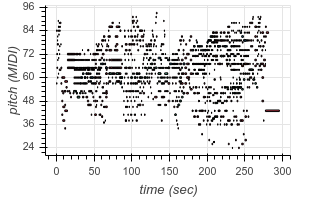 |
|
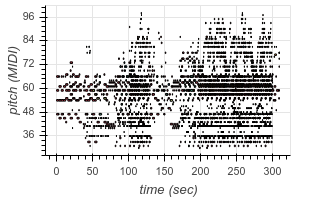 |
|
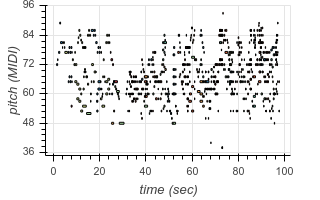 |
Our approach to treating music transcription as a multi-task problem by training across a mixture of datasets makes certain issues more salient compared to the single-task setup:
- Alignment: Music transcription datasets can contain systematic timing biases related to the method by which note onsets and offsets are annotated. For example, the MAESTRO dataset is precisely captured using a Disklavier, and other datasets e.g. GuitarSet and URMP use a combination of automatic and human-edited annotations. MusicNet in particular seems to have a number of alignment errors. While a model could systematically learn the annotator biases for an individual dataset, this is unlikely when training on a mixture of datasets. We made no attempt to fix alignment issues in the datasets.
- Velocity: MIDI velocities are coded differently (or not at all) across datasets, with no standard measurement or encoding methodology. We address this issue by removing velocity from our output vocabulary; however, as velocity is important to capturing musical expressiveness, multi-task learning of models with velocity is an important area for future work.
The task of multi-instrument music transcription is a challenging one and, as some of our examples show, there is much room for improvement. For example, the model sometimes changes its predicted instrument mid-phrase — leading to e.g. a violin that abruptly changes to cello — and the model can struggle to correctly identify strange or novel-sounding instruments.
Still, we’re excited about our recent progress on automatic music transcription, and we hope you are too! For further details, see our paper at ISMIR 2021, our recent arXiv paper, and our open-source code.