Amidst all the successes around complex sequence-to-sequence language models such as Music Transformer for music generation, we’re left with a big question: how do we actually interact with these models in our creative loop? If we have, say, a snippet of a song that we really like, is there a way for our model to generate musical pieces that sound similar in style?
We introduce the Transformer autoencoder, a step towards giving users control over both the global and local structure of a generated music sample. In particular, the model enables using an existing MIDI file as input to generate a performance in a similar style, or harmonize a specific melody in the style of a given performance.
| Performance used for style conditioning |
| Generated performance in the specified style |
How does it work?
The Transformer autoencoder is built on top of Music Transformer’s architecture as its foundation. As a refresher, Music Transformer uses relative attention to better capture the complex structure and periodicity present in musical performances, generating high-quality samples that span over a minute in length. We encourage you to check out the paper as well as the blog post for more details.
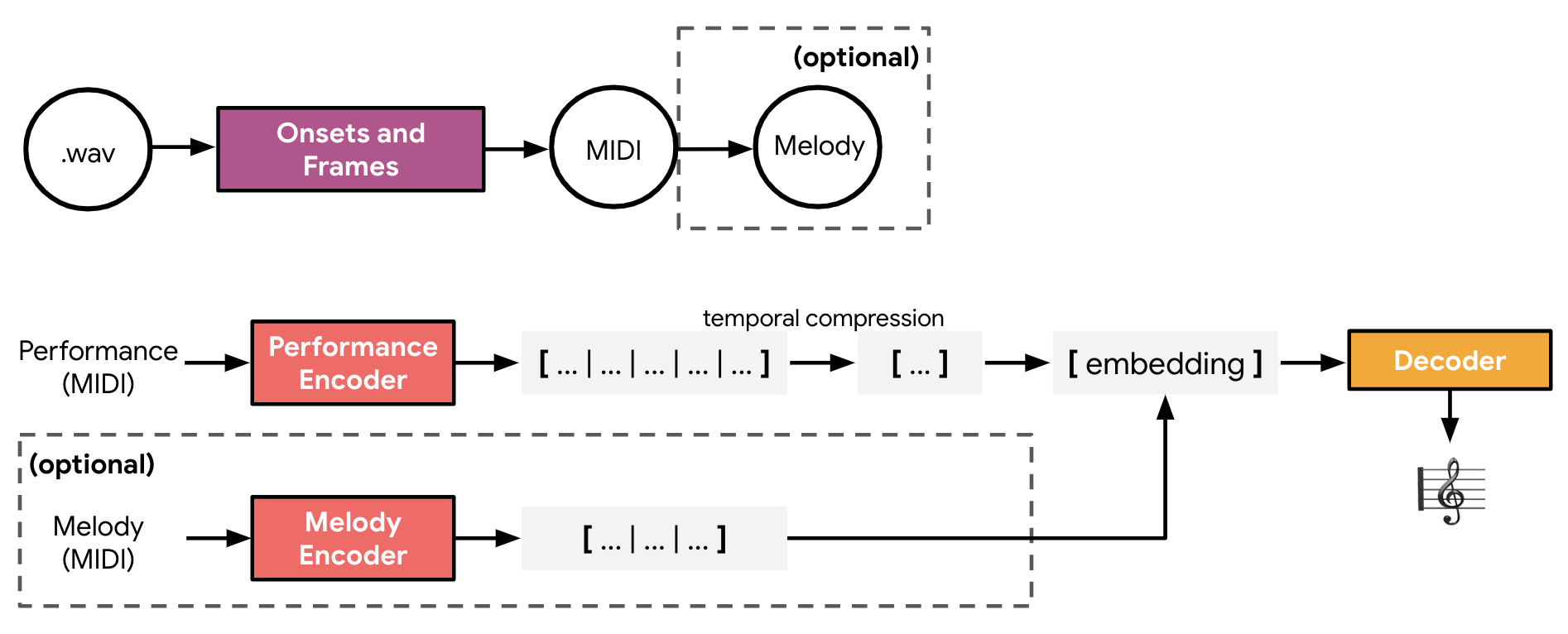
As shown in the flowchart above, we first transcribe .wav data files into MIDI using the Onsets and Frames model, then encode them into performance representations. The Transformer autoencoder’s performance encoder takes as input the performance conditioning signal, and we mean-aggregate the output embedding across time to learn a global representation of its style. The decoder is allowed to attend to this style vector, and this bottleneck prevents the model from simply memorizing the input at reconstruction time during training:
| Performance used for style conditioning |
| Generated performance in the specified style |
To harmonize with an input melody and performance, we use a separate melody encoder in addition to the performance encoder to embed the respective inputs. These two intermediate representations of melody and performance are then aggregated to form a single vector input into the decoder. We explore various ways of combining the embeddings in the arXiv paper.
| Melody to harmonize |
| Performance used for style conditioning |
| Generated accompaniment in the specified style |
You can view the open-sourced code here to train your own model and experiment with the different types of conditional generation tasks. To learn more about the Transformer autoencoder, please check out our arXiv paper!