Editorial Note: In August of 2020, Magenta partnered with Gray Area to host BitRate: a month-long series focused on experimenting with the possibilities of Music and Machine Learning. Here is a blog post from one of our top projects, explaining their project in more detail. Learn more about BitRate and view additional submissions on the event page.
Note that Magenta also has a dataset with a similar name: MAESTRO Dataset

This past August, 2020, we participated in the Bitrate: Machine Learning & Music Series hackathon hosted by the Magenta team and Grey Area. We leveraged the Magenta.js library to create Maestro, an application that combines music theory with practical lessons for music enthusiasts. Through Maestro’s music visualization, singers can see the exact pitch they need to belt and can get immediate feedback on how well they’re singing. In this blog post, we’ll be sharing our insights on how we:
- designed and created a unique note visualizer
- used Magenta’s music generation models for vocal tests
- implemented the singing experience: the interface, pitch detection, and note generation
- envision the next steps for Maestro
Motivation and Goals
While Magenta explores the potential of machine learning to create music, Maestro is an application that uses the foundation of Magenta to explore how machine learning can be used to teach music. Maestro is dedicated to helping users learn while providing instant feedback on performance even in the absence of a teacher. Taking inspiration from sites such as Khan Academy, Maestro provides video singing lessons followed by hands-on practice where students try singing certain notes and arpeggios to see what they’ve learned.
Music Visualization
The central part of this project is Maestro’s musical notes visualizer– an intuitive musical guide which helps the singer see if they are belting their notes in the correct pitch. We designed and implemented two different visualizers for two different purposes. The visualizers rely on similar designs, with the played note highlighted in teal and the detected note highlighted in violet. This provides the singer with instant feedback on how close they are singing to the intended note.
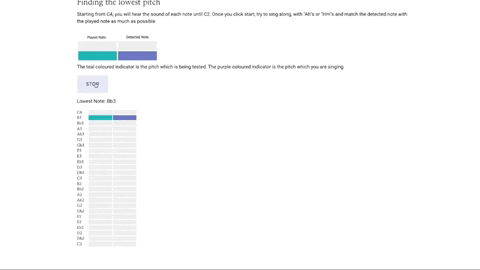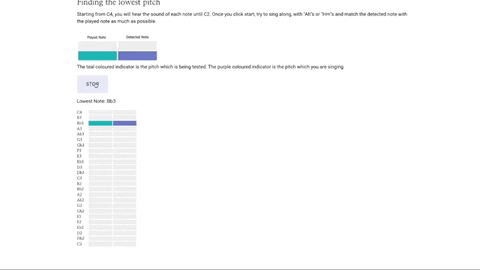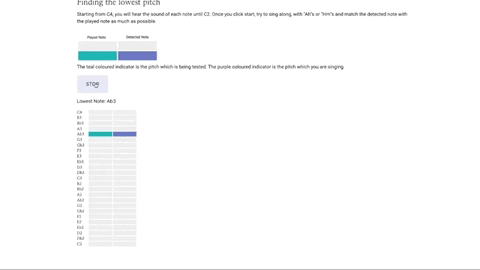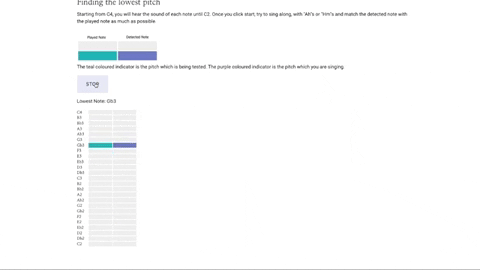
This is a static visualizer with two columns and moves vertically with time. We created this sequencer to test a singer’s vocal range, taking them from middle C to the lowest note and highest note they can sing.
A static visualizer can be used for other applications as well, such as ascending and descending a specific scale, or learning to reach one particular note, to name a few.

This is a dynamic visualizer with multiple columns and moves horizontally through time. We created this sequencer for all our practice sessions when singers are given a sequence of notes to sing. For this, we implemented a Sequencer class which we discuss in our Technical Implementations section.
This visualizer is mainly used in our practice sessions and in the vocal tests after a group of practice sessions. The Sequence visualizer, as opposed to the Range visualizer, only consists of a selected range of notes. This is because the range is personalized to a singer’s vocal range, and because the focus here is the action of singing, where note jumps are uncommon. As a person’s vocal range expands, we would add more rows to this sequencer.
Music Generation for Tests
The practice sessions for a lesson have a predetermined set of notes and scales for a user to sing. This allows a user to go back and redo practices multiple times until they prefect them. For the testing portion, we wanted the notes in the tests to be randomly generated. That way the user would have to be able to sing a note in any context, not just within a certain scale or practice session. Furthermore, we wanted the generated notes to be different each time they did the test so that someone does not simply redo the test multiple times until they pass. In order to pass the test, a user will have to be comfortable with singing different notes.
One of the key aspects of learning is to practice and test one’s newly learned ability. We tried to incorporate a unique testing module, such that it generates random test notes every time it is accessed. In order to achieve such randomness in notes generation, We leveraged ImprovRNN’s model provided by Magenta. The ImprovRNN models are pre-trained LSTM based neural network models that allow you to produce a specific chord. For demo purposes, we made sure the module only generates random notes around “C4”. There is a lot of potential in random notes generation using Magenta. This can be used to create customized tests for users, based on their needs and requirements.
Technical Implementation and Challenges

Initially, we were drawn towards the Magenta visualizer that accompanies its player, which displays the notes being played, relative to other notes. However, we faced two hurdles here which steered us away from using this built-in implementation.
- We were unable to customize the visualizer to display the notes the user is currently singing. We didn’t want to have two separate visualizers since it would be harder for the user to look at both visualizers at the same time, so we needed a different solution.
- The notes visualized did not have a specific interval and were relatively placed above or below each other. For an application that teaches specific musical notes, how do we tell the singer they are supposed to sing a C#3 and then a E#3? We were unable to add a legend or an axis to the Magenta visualizer.
In order to implement the visualizer, we used a Nexus UI Sequencer component. The sequencer allows you to customize which blocks in a 2D matrix are “on” and “off”. We were able to use “on” blocks to represent notes on a scale. Normally, the sequencer “on” blocks are all the same color. However, using some CSS and HTML, we were able to update the color property of the blocks to have the sequencer support multiple colors. Thus we used the “on” blocks to represent the notes the user needs to sing as well as the note they are currently singing.
One downside was that the custom code we wrote slowed down the rendering time for the sequencer slightly. The main challenge with both the Magenta and Nexus UI sequencer is the limited customization available. This highlights that as we find more innovative ways to generate music with machine learning, we also need innovative ways to visualize and display the music generation process. We look forward to seeing how magenta can add customization capabilities to their visualization components.
Pitch Detection
Detecting pitch is an important element of Maestro and we leveraged ml5’s pitch detection model to accomplish this task. A challenge we faced was that the microphone of the singer would often pick up on background noise or random scratches from the microphone surface, which would cause really random notes to be visualized, even notes that were outside a human’s ability.
To resolve this, we implemented several functions that only consider and visualize “reasonable” notes, meaning notes that are less than one octave away from the note that is being sung, or notes that are impossible for humans to produce.
Music Generation with Magenta RNNs
We utilized the MusicRNN model to randomly generate the test notes for the tests. In particular we used the ImproveRNN pre-created model provided out of the box by magenta. The ImprovRNN model uses an LSTM neural network to generate music but allow you to specify underlying chord progressions. Since for each test we had certain notes or scales we were interested in testing, we would provide those notes as the “seed” for the model. The model would output a continuation for these notes that we then used as the test for the lesson.
let seed = {
notes: [
{ pitch: 60, startTime: 0.0, endTime: 4.0 },
{ pitch: 62, startTime: 4.0, endTime: 8.0 },
{ pitch: 60, startTime: 8.0, endTime: 12.0 },
{ pitch: 62, startTime: 12.0, endTime: 16.0 },
{ pitch: 60, startTime: 16.0, endTime: 20.0 },
],
tempos: [{
time: 0,
qpm: 120
}],
totalTime: 20.0
};
var rnn_steps = 50;
var rnn_temp = 1.0;
var chord_prog = ['C'];
const qns = mm.sequences.quantizeNoteSequence(seed, 1);
var notes = await melodyRnn.continueSequence(qns, rnn_steps, rnn_temp, chord_prog);
Though the model is pretrained, it still needs to be loaded by the browser before we can run the music generation code. The large size of the model meant that when running it on computers with less processing power, the music generation was slow with a noticeable lag. Even on newer computer models with better processing power, there is a slight delay between the page loading, and the model generating the practice test. The slow load times were a factor in us choosing to only auto generate tests and not the practice lessons as well. Right now, Maestro has a heavy front end due to the machine learning model it loads. Going forward, we would like to explore how we can optimize the load times of the models to lead to a better user experience.
Future Directions
Currently we demonstrate the potential to leverage Magenta to play notes and randomly generate tests for a student to practice their singing. In the future, we would like to integrate machine learning into the practice session as well. Maestro could generate practice sessions personalized for the user. So if there are certain notes a student struggles to sing, they will appear more often within the practice sessions. For example, if a student struggles to hit the D note, it would appear more often. We could create a progress section to allow users to see how they perform on various notes and allow them to track their progress.
Furthermore, we see the potential of Maestro being extended into a global platform for music teachers to upload their own lessons. This would allow users to find the teaching style that works best for them rather than following one predetermined path. The lessons could move beyond singing lessons to also include various instruments, such as piano teaching. These big goals are possible because of ml5’s efficient pitch detection model and Magenta’s vast resources for musical playback and generation.