Update (9/16/19): Play with Music Transformer in an interactive colab!
Generating long pieces of music is a challenging problem, as music contains structure at multiple timescales, from milisecond timings to motifs to phrases to repetition of entire sections. We present Music Transformer, an attention-based neural network that can generate music with improved long-term coherence. Here are three piano performances generated by the model:
Similar to Performance RNN, we use an event-based representation that allows us to generate expressive performances directly (i.e. without first generating a score). In contrast to an LSTM-based model like Performance RNN that compresses earlier events into a fixed-size hidden state, here we use a Transformer-based model that has direct access to all earlier events.
Our recent Wave2Midi2Wave project also uses Music Transformer as its language model.
Transformer with Relative Attention
While the original Transformer allows us to capture self-reference through attention, it relies on absolute timing signals and thus has a hard time keeping track of regularity that is based on relative distances, event orderings, and periodicity. We found that by using relative attention, which explicitly modulates attention based on how far apart two tokens are, the model is able to focus more on relational features. Relative self-attention also allows the model to generalize beyond the length of the training examples, which is not possible with the original Transformer model.
The previous relative attention paper used an algorithm that was overly memory intensive for longer sequences. We instead use our new algorithm for relative self-attention that dramatically reduces the memory footprint, allowing us to scale to musical sequences on the order of minutes.
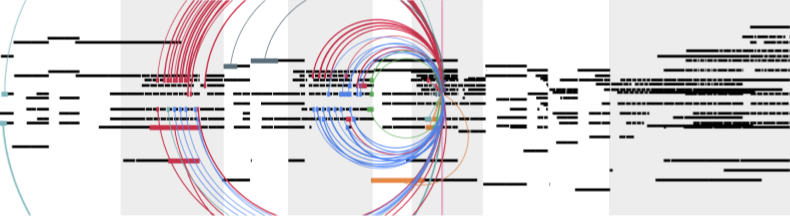
Visualizing Self-Reference
In the following example, the model introduces a rhythmically quirky tremolo motif (identifiable through the denser sections with broken lines in the opening visualization), then repeats and varies it several times in the piece (manually marked by grayed out blocks), culminating with a quick succession to build tension. To see the self-reference, we visualized the last layer of attention weights with the arcs showing which notes in the past are informing the future. We see that the model focuses its attention between the various tremolo blocks and is able to skip over sections that are less relevant:
Continuations of a Given Motif
Let’s listen to a set of examples where we primed Performance RNN, Transformer, and Music Transformer with the same initial motif and asked each of them to generate continuations.
Here’s the primer, a motif from Chopin’s Black-Key Etude:
Performance RNN, an LSTM
And here’s Performance RNN continuing the performance:
The model seems to “forget” about the primer almost immediately. While LSTM-based models are able to generate music that sounds plausible at time scales of a few seconds or so, the lack of long-term structure is apparent. As a consequence, Performance RNN is unable to generate coherent continuations to a user-specified primer performance.
Vanilla Transformer
In contrast, Transformer is able to reuse the primer and maintain some degree of consistency. But since this particular model was trained on half the sample length (also the case for other models in this experiment), the second half of the sample completely deteriorates.
Music Transformer
Music Transformer, on the other hand, is able to continue playing with consistent style throughout, creating multiple phrases out of the motif:
Below are two more samples showing the model taking the same motif on a different spin. This opens up the potential for users to specify their own primer and use the model as a creative tool to explore a range of possible continuations.
Unconditioned Samples
Here are a few more unconditioned samples (i.e. no primer) generated by Music Transformer:
“Failure” Samples
We collected some examples generated by Music Transformer that had clear flaws, but had so much character and dramatic arc that we thought we’d include them for fun. Some “failure” modes include too much repetition, sparse sections, and jarring jumps.
Score Conditioning
We can also provide a conditioning sequence to Music Transformer as in a standard seq2seq setup. One way to use this is to provide a musical score for the model to perform.
Unfortunately the requisite training data with matched score-performance pairs is limited; however, we can ameliorate this to some extent by heuristically extracting a score-like representation (e.g. melody, chords) from a set of training performances. Here we trained a Music Transformer model to map heuristically-extracted melody to performance, and then asked it to play the Twinkle Twinkle Little Star melody (with chords unspecified):
Here’s an example where we trained a Music Transformer model to map heuristically-extracted chords to performance, and then asked it to play the chord progression from Hotel California:
Coming Soon
We are in the process of releasing the code for training and generating with
Music Transformer, along with pre-trained checkpoints. The relative attention
functionality is already available in the Tensor2Tensor
framework by setting the self_attention_type hparam to
"dot_product_relative_v2", and we are in the process of releasing a Tensor2Tensor
problem
for music performance generation.
In the meantime, you can read more about Music Transformer in our arXiv paper.
Bonus Content
Our former intern Chris Donahue (creator of Piano Genie) liked one of the Music Transformer samples at the top of the page so much he decided to learn to play it himself. And he really nailed it. Here’s a video of Chris’s performance:
To bring the blog full circle, we’re reshowing our opening sample resynthesized using a WaveNet model from our recent Wave2Midi2Wave project. And you’ll know it’s neurally synthesized when you hear the page turn (that sounds like a breath) at the 49 second mark, matching exactly the beginning of a phrase.
Acknowledgements
This blog post is based on the Music Transformer paper authored by Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Noam Shazeer, Ian Simon, Curtis Hawthorne, Andrew M. Dai, Matthew D. Hoffman, Monica Dinculescu and Douglas Eck.
@article{huang2018music,
title={Music Transformer: Generating Music with Long-Term Structure},
author={Huang, Cheng-Zhi Anna and Vaswani, Ashish and Uszkoreit, Jakob and Shazeer, Noam and Hawthorne, Curtis and Dai, Andrew M and Hoffman, Matthew D and Eck, Douglas},
journal={arXiv preprint arXiv:1809.04281},
year={2018}
}
Special thanks to Ashish Vaswani and Tim Cooijmans for their feedback on this blog post, Adam Roberts for the WaveNet synthesis in the bonus section, and everybody on the Magenta team for their constant support.
All audio clips in this post were rendered with Alexander Holm’s Salamander piano samples.